请求量太大扛不住怎么办?进来学一招


hello,大家好呀,我是小楼。
上篇文章《一言不合就重构》 说了我最近重构的一个系统,虽然重构完了,但还在灰度,这不,在灰度过程中又发现了一个问题。
背景
这个问题简单说一下背景,如果不明白可以看上篇文章 ,不想看也没关系,这是个通用的解法,后面我会总结抽象下。
在上篇文章的最后提到对每个摘除的地址做决策时,需要顺序执行,且每一个要摘除的地址都要实时获取该集群的地址信息,以便做出是否需要兜底的决策。
当被摘除的机器非常多时,获取地址信息的请求量就会非常大,对注册中心造成了不小的压力。
请求数据源的接口如下所示(其中 cuuid 是集群的 id)
type Read interface {
ListClusterEndpoints(ctx context.Context, cuuid string) ([]ptypes.Endpoint, error)
}
相信大家也能理解这个非常简单的背景并且能想到一些解法。每次决策需要按 cuuid 获取集群,也就是单个单个地获取实时集群地址信息,由于是实时信息,缓存首先排除,其次自然而然地能想到如果能将请求合并一下,是不是就能解决请求量大的问题?
难点
如果只是改逻辑合并一下请求,吭哧吭哧改代码就完了,也不值得写这篇文章了,如何改最少的代码来实现合并请求才是最难的。
解法
那天遇到这个问题,晚上辗转反侧想到了这个解法,其实主要也是参考 Go http client 的实现,都说看源码没用,这不就是用处么?
Read 数据源接口定义保持不变,也就是上层的业务代码完全不用改,只需要把 ListClusterEndpoints 的实现换掉。
我们可以用一个队列把每个请求入队,入队列以后,调用方阻塞,然后起一些协程去队列里取一批请求参数,发起批量请求,响应之后唤醒阻塞的调用方。
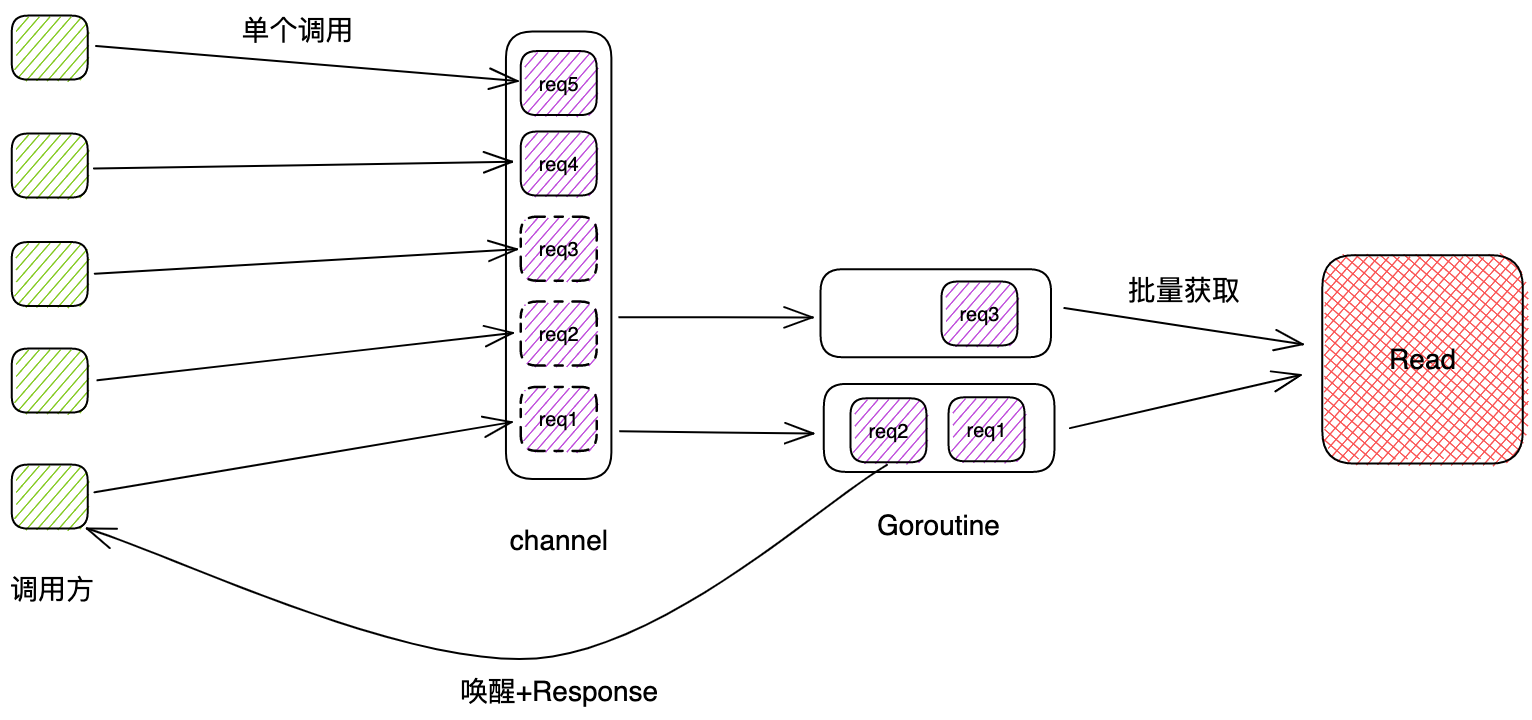
为此,我们实现一个可以阻塞并被其他协程唤醒的工具:
type token struct {
value interface{}
err error
}
type Token chan token
func NewToken() Token {
return make(Token, 1)
}
func (t Token) Done(value interface{}, err error) {
t <- token{value: value, err: err}
}
func (t Token) Wait(timeout time.Duration) (value interface{}, err error) {
if timeout <= 0 {
tk := <-t
return tk.value, tk.err
}
select {
case tk := <-t:
return tk.value, tk.err
case <-time.After(timeout):
return nil, ErrTokenTimeout
}
}
其次,定义队列和其他参数:
type DataSource struct {
paramCh chan param
readTimeout time.Duration
concurrency int
step int
}
type param struct {
cuuid string
token Token
}
替换掉原来 ListClusterEndpoints 的实现:
func (p *DataSource) ListClusterEndpoints(ctx context.Context, cuuid string) ([]ptypes.Endpoint, error) {
req := param{
cuuid: cuuid,
token: NewToken(),
}
select {
case p.paramCh <- req:
default:
return nil, fmt.Errorf("list cluster endpoints write channel failed")
}
value, err := req.token.Wait(p.readTimeout)
if err != nil {
return nil, err
}
eps, ok := value.([]ptypes.Endpoint)
if !ok {
return nil, fmt.Errorf("value is not endpoints")
}
return endpoints, nil
}
再起几个协程来处理任务:
func (p *DataSource) startListClusterEndpointsLoop() {
for i := 0; i < p.concurrency; i++ {
go func() {
for {
reqs := p.getListClusterEndpointsReqFromChan()
p.doBatchListClusterEndpoints(reqs)
}
}()
}
}
最关键的是 getListClusterEndpointsReqFromChan 的实现,既不能让协程空跑,这样太消耗cpu,又要能及时地取到一批参数,我们采取的方法是先阻塞地获取一个参数,如果没数据则阻塞,如果有数据,继续取,直到数量达到上限或者取不到数据为止,此时这一批数据就可以批量地进行调用了。
func (p *DataSource) getListClusterEndpointsReqFromChan() []param {
reqs := make([]param, 0)
select {
case req := <-p.paramCh:
reqs = append(reqs, req)
for i := 1; i < p.step; i++ {
select {
case reqNext := <-p.paramCh:
reqs = append(reqs, reqNext)
default:
break
}
}
}
return reqs
}
最后
这个方法很简单,但是有一些要注意的地方,得做好监控,比如调用方单个请求的QPS、RT,实际批量请求的QPS、RT,这样才好计算出处理协程开多少个合适,还有队列写入失败、队列长度等等监控,当容量不足时及时做出调整。
推荐阅读
与本文相关的文章也顺便推荐给你,如果觉得还不错,记得关注、点赞、在看、分享。
- 《一言不合就重构》
- 《如何给注册中心锦上添花?》
- 《如何组装一个注册中心?》
- 《服务探活的五种方式》
- 《4个实验,彻底搞懂TCP连接的断开》
搜索关注微信公众号”捉虫大师”,后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践;
