使用python爬取微博评论


最近在复习以前学习的python爬虫内容,就拿微博来练了一下手,这个案例适合学习爬虫到中后期的小伙伴,因为他不是特别简单也不是很难,关键是思路,为什么说不是很难呢?因为还没涉及到js逆向,好了话不多说开干。
(1)找到要爬取的页面,如下:
(2)点开评论,拉到最下方,如下位置:

点击“点击查看”进入另一个页面,如下所示:

这里会显示更多评论,但是不是全部,随便复制一条评论的内容,然后到源码里手搜索,发现是不存在的,这就说明我们想要的内容不在源码里,那就是二次加载的了,当我们第一次请求服务器的时候,服务器返回源码,但是里面没有评论,然后浏览器会二次请求服务器,这时服务器返回评论数据,形式为json数据,然后js会把数据加载进页面。好的,原理懂了,那么现在就开始正式的爬取了。
(3)打开浏览器的开发者工具,切换到网络选项,如果没抓到包,那就刷新一下页面,发现如下所示:
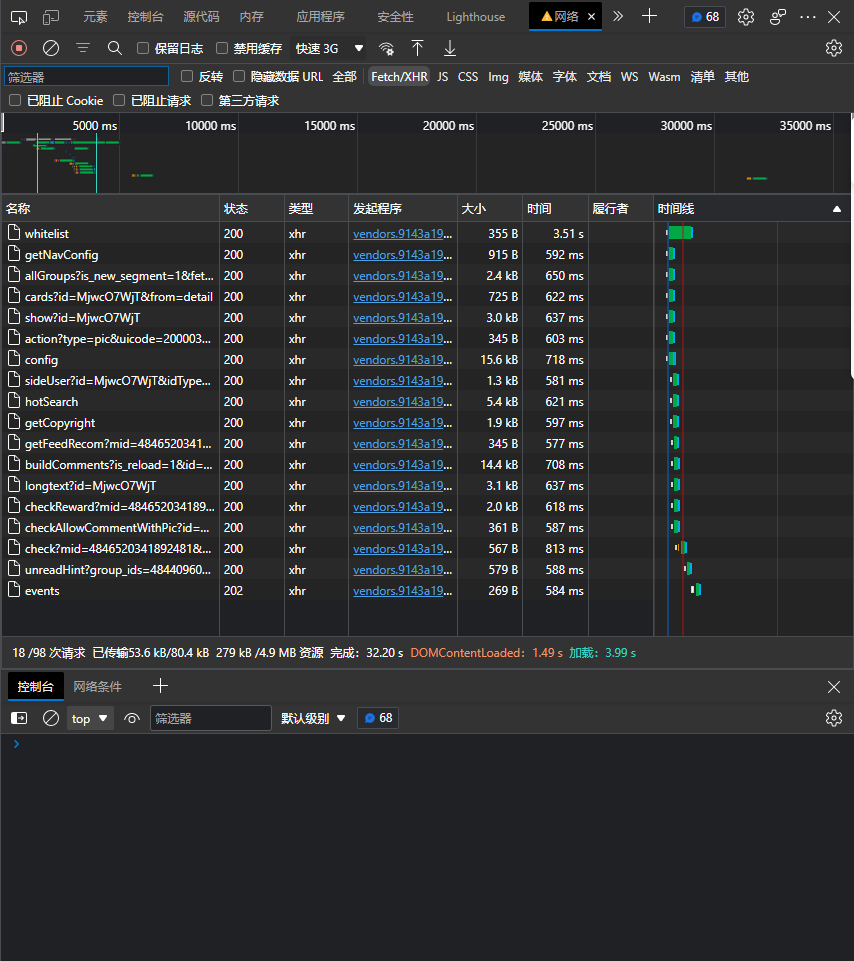
记得切换到Fetch/XHR,这样我们要找评论所在的数据包时就会更加容易,一个一个的点点看,你会发现评论数据在buildComments?is_reload=1……里面,然后再看一下参数,如下所示:

再看一下标头,如下所示:

那么我们现在基本可以确定只要向标头里的地址发送get请求,带上参数,就可以得到json数据,但是,要记得这不是全部数据,当你继续往下滑查看评论时,他会继续请求数据,这时我们在抓包工具里进行过滤,就可以看到如下所示:

点开查看,发现请求所带的参数不同了,如下所示:

对比后发现,多了flow,max_id,并且count也变成了20,那么我们继续滑动,查看其他的请求,会发现除了max_id其他参数是不变的,经过我的试验,flow参数不是必要的,可以不带,因为有的帖子有这个参数有的帖子没有,其他的每个帖子都有,我们再看看其他的帖子发现不同的帖子id,max_id,uid是不同的,所以现在就确定了这三个参数是变化的。首先你会发现对于不同的帖子,uid就在地址里,应该就是作者的id,因为这个在源码里也是不存在的,所以我们就使用输入的方式获取uid,对于id,你会发现无论在地址里,还是源码里都找不到它,我经过仔细的观察,发现这个id在show?id=MjwcO7WjT这个数据包里,而他的参数id=MjwcO7WjT就在地址里,这个参数我们也采用输入的方式获取。现在就剩下max_id了,我们发现第一次请求不需要max_id,之后的都要,再观察一下第一个数据包里的max_id,正好是第二次请求的参数max_id,那么此时你可能已经有了猜想,每一次请求返回的json数据的max_id就是下一个请求的参数,经过我的辛苦劳动,证实我们的猜想是对的。
(4)现在我们已经把思路给理清了,那么代码就不多讲解了,我就直接给了,但是要注意headers里的cookie要换成自己的,这里的cookie为虚假的。这里说一下cookie的作用,带了你自己的cookie就相当与你登录了微博,现在就这样简单解释吧。
(5)完整代码:(注:这里没有爬取子评论,也就是回复)
import time
import csv
import requests
def getArticleId(id_str):
"""
:param id_str: 需要解密的id字符串
:return:
"""
url_id = "https://weibo.com/ajax/statuses/show?id={}".format(id_str)
resp_id = requests.get(url_id, headers=headers)
article_id = resp_id.json()["id"]
return article_id
def get_one_page(params):
"""
:param params: get请求需要的参数,数据类型为字典
:return: max_id:请求所需的另一个参数
"""
url = "https://weibo.com/ajax/statuses/buildComments"
resp = requests.get(url, headers=headers, params=params)
data_list = resp.json()["data"]
for data in data_list:
data_dict = {
"screen_name": data["user"]["screen_name"],
"profile_image_url": data["user"]["profile_image_url"],
"location": data["user"]["location"],
"created_time": data["created_at"].replace("+0800", ""),
"text": data["text_raw"],
}
print(
f"昵称:{data_dict["screen_name"]}
头像:{data_dict["profile_image_url"]}
地址:{data_dict["location"]}
发布时间:{data_dict["created_time"]}
评论内容:{data_dict["text"]}")
print("=" * 90)
saveData(data_dict)
max_id = resp.json()["max_id"]
if max_id:
return max_id
else:
return
def get_all_data(params):
"""
:param params: get请求需要的参数,数据类型为字典
:return:
"""
max_id = get_one_page(params)
params["max_id"] = max_id
params["count"] = 20
while max_id:
params["max_id"] = max_id
time.sleep(.5)
max_id = get_one_page(params)
def saveData(data_dict):
"""
:param data_dict: 要保存的数据,形式为dict类型
:return:
"""
writer.writerow(data_dict)
if __name__ == "__main__":
uid = input("请输入作者id:")
id_str = input("请输入您要爬取的微博话题的英文id:")
fileName = input("请输入要保存的文件名:")
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46 ",
"x-requested-with": "XMLHttpRequest",
"referer": "https://weibo.com/1779719003/{}".format(id_str),
"cookie": "替换为自己的cookie",
"x-xsrf-token": "-YYOKoKzkyMDGhDmhVSCLqpD"
}
id = getArticleId(id_str) # 获取参数需要的真正id
# 向csv文件写入表头
header = ["screen_name", "profile_image_url", "location", "created_time", "text"]
f = open(f"csv/{fileName}.csv", "w", encoding="utf-8", newline="")
writer = csv.DictWriter(f, header)
writer.writeheader()
# get请求的参数
params = {
"is_reload": 1,
"id": id,
"is_show_bulletin": 2,
"is_mix": 0,
"count": 10,
"uid": int(uid)
}
get_all_data(params)
f.close()
print("数据爬取完毕。")
效果如下:

注意:csv文件路径修改为自己的,如果爬取过程中出现400 bad request,那么你被发现了是爬虫,可以考虑把睡眠时间改长些,如果还不行的话,有基础的伙伴们可以使用ip代理或使用随机的user-agent。
