这次我把Redis数据类型写出了花✿❀🎉~~~


1. String
字符串是 Redis 最基本的数据类型,不仅所有 key 都是字符串类型,其它几种数据类型构成的元素也是字符串。注意字符串的长度不能超过 512M。
1.1 编码方式(encoding)
字符串对象的编码可以是 int ,raw 或者 embstr 。
- int 编码:保存的是可以用 long 类型表示的整数值。
- embstr 编码:保存长度小于 44 字节的字符串(redis3.2 版本之前是 39 字节,之后是 44 字节)。
- raw 编码:保存长度大于 44 字节的字符串(redis3.2 版本之前是 39 字节,之后是 44 字节)。
<
int 编码是用来保存整数值,而 embstr 是用来保存短字符串,raw 编码是用来保存长字符串。
1.2 raw 编码
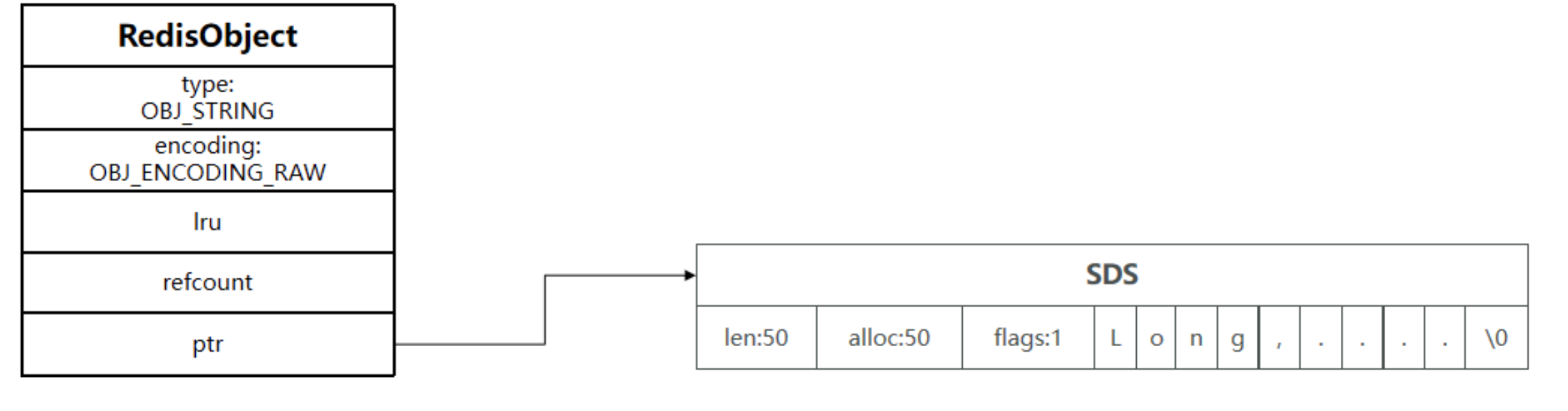
*ptr 指向实际 SDS 存储位置。内存不连续
1.3 embstr 编码

内存连续,意味着 redis 在申请内存空间时只需要调用一次申请内存函数,减少用户态内核态交换,效率高。
1.4 int 编码
如果存储的字符串是整数值,并且大小在 LONG_MAX 范围内,则会采用 INT 编码:直接将数据保存在 RedisObject 的 ptr 指针位置(刚好 8 字节),不再需要 SDS 了。
1.5 总结
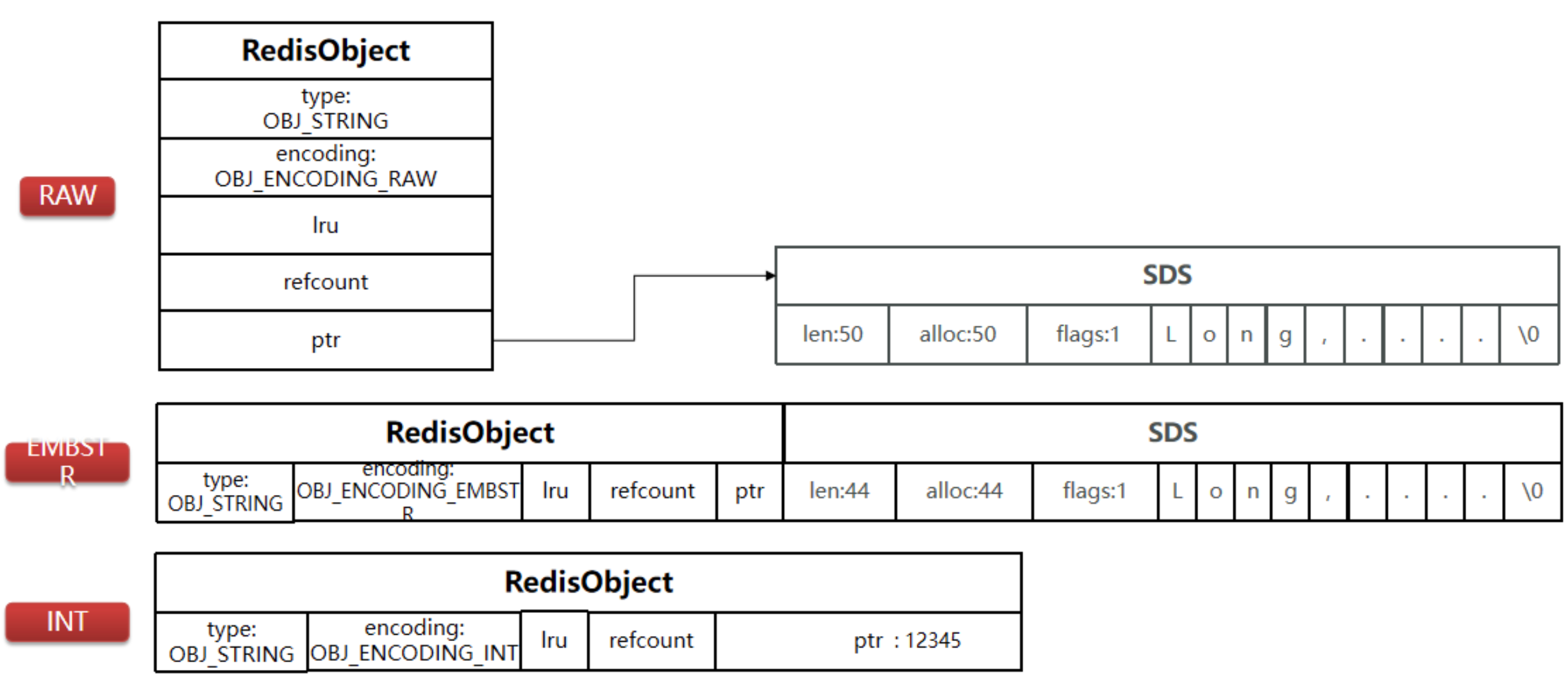
2. List
list 列表,它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表结构。
2.1 编码方式(encoding)
列表对象的编码是 quicklist。 (之前版本中有 linkedList 和 ziplist 这两种编码。进一步的,目前 Redis 定义的 10 个对象编码方式宏名中,有两个被完全闲置了,分别是: OBJ_ENCODING_ZIPMAP 与 OBJ_ENCODING_LINKEDLIST。 从 Redis 的演进历史上来看,前者是后续可能会得到支持的编码值(代码还在), 后者则应该是被彻底淘汰了)
2.2 内存布局

3. Set
集合对象 set 是 string 类型(整数也会转换成 string 类型进行存储)的无序集合。注意集合和列表的区别:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
3.1 编码方式(encoding)
集合对象的编码可以是 intset 或者 hashtable; 底层实现有两种,分别是 intset 和 dict 。 显然当使用 intset 作为底层实现的数据结构时,集合中存储的只能是数值数据,且必须是整数;而当使用 dict 作为集合对象的底层实现时,是将数据全部存储于 dict 的键中,值字段闲置不用.
3.2 内存布局

3.3 编码转换
当集合同时满足以下两个条件时,使用 intset 编码:
- 集合对象中所有元素都是整数
- 集合对象所有元素数量不超过 512
不能满足这两个条件的就使用 hashtable 编码。第二个条件可以通过配置文件的 set-max-intset-entries 进行配置。
4. Zset
和上面的集合对象相比,有序集合对象是有序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
4.1 编码方式(encoding)
- SkipList & HT(Dict):SkipList 可以排序,并且可以同时存储 score 和 ele 值(member);HT 可以键值存储,并且可以根据 key 找 value
- ZipList :当 节点 entry 数量 小于 128 并且 每个节点大小小于 64kb 时采用
4.2 内存结构
SkipList & HT(Dict)

ZipList
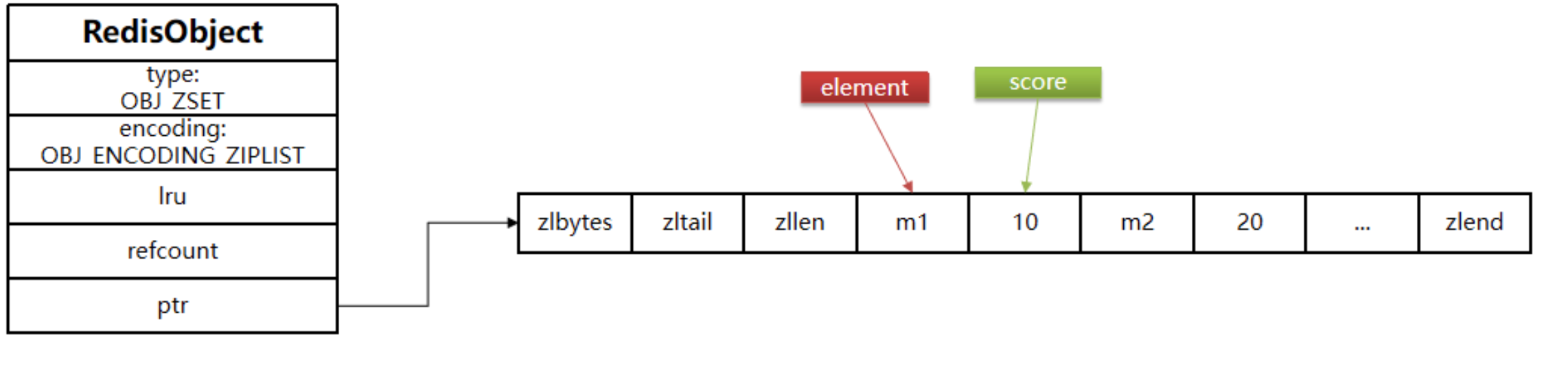
当元素数量不多时,HT 和 SkipList 的优势不明显,而且更耗内存。因此 zset 还会采用 ZipList 结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于 zset_max_ziplist_entries,默认值 128
- 每个元素都小于 zset_max_ziplist_value 字节,默认值 64
ziplist 本身没有排序功能,而且没有键值对的概念,因此需要有 zset 通过编码实现:
- ZipList 是连续内存,因此 score 和 element 是紧挨在一起的两个 entry, element 在前,score 在后
- score 越小越接近队首,score 越大越接近队尾,按照 score 值升序排列
5. Hash
哈希对象的键是一个字符串类型,值是一个键值对集合。
5.1 编码方式(encoding)
哈希对象的编码可以是 ziplist 或者 hashtable;对应的底层实现有两种,一种是 ziplist, 一种是 dict。
5.2 内存布局
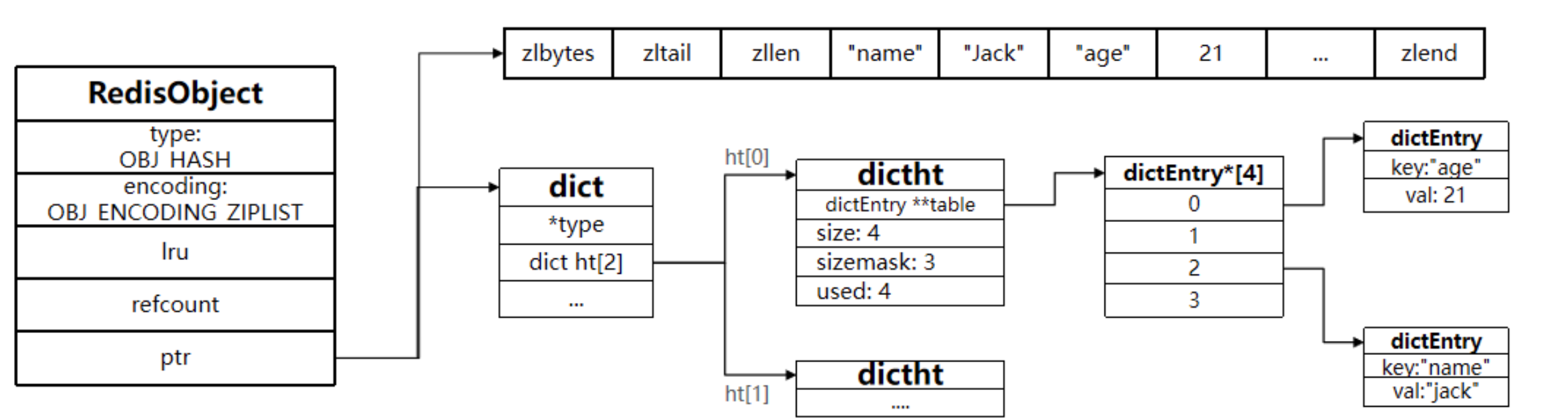
Hash 结构与 Redis 中的 Zset 非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset 的键是 member,值是 score;hash 的键和值都是任意值
- zset 要根据 score 排序;hash 则无需排序
当 Hash 中数据项比较少的情况下,Hash 底层才⽤压缩列表 ziplist 进⾏存储数据,随着数据的增加,底层的 ziplist 就可能会转成 dict,具体配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
