《python网络爬虫和信息提取》:中国大学排名(附更改前后的代码)


python网络爬虫和信息提取
《python网络爬虫和信息提取》是北京理工大学的一门网络课程(中国大学MOOC(慕课))。
偶然机会我在网上学习了这门课程,中国大学排名是老师在课程里举的一个例子。作为一个认真学习的python菜鸟,我把老师的代码认真敲打出来,一运行却出现问题。
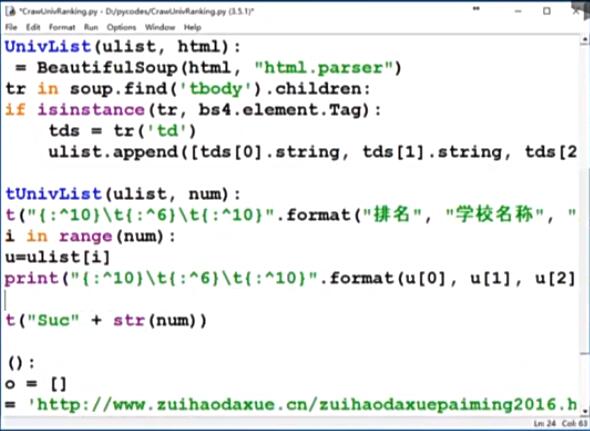
是老师的代码有问题么?我把网址输入浏览器,却打不开,搜索了一下,发现几年后的今天,原网站进行了升级,从域名到网站结构,都发生了翻天覆地的变化,原代码当然不适用了。但在网上搜索,还能看到原封不动照搬老师代码的所谓学习心得,误人不浅,故把自己真正的学习心得放到这里,供和我一样的菜鸟参考。
首先打开网页对应清华大学排名源代码部分,对相关标签进行分析。

经过分析发现,名次1是tds[0],校名“清华大学”却并不是单独的tds[1],而是和英文校名、双一流/211一起,都属tds[1],在原代码tds[1].string基础上修改为:
tds[1](“a”)[0].string,tds[1](“a”)[1].string,tds[1](“p”)[0].string,分别提取出了校名、英文校名、双一流/211等信息,但不知为什么,用tds[2].string,tds[3].string没能正常提取出省市(北京)、类别(综合)的信息,仍显示为None,用tds[4].string可以正常提取总分(999.4)信息。请高手们指正。
修改后的代码为:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
print(r.request.url)
r.encoding = r.apparent_encoding
print(r.text[:1000])
return r.text
except:
# return ""
print("网页抓取失败!")
def fillUnivList(ulist,html):
soup = BeautifulSoup(html, "html.parser")
# print("title=",soup.title)
for tr in soup.find("tbody").children:
if isinstance(tr,bs4.element.Tag):
tds = tr("td") # 列表形式
# print("tds=",tds)
ulist.append([tds[0].string,tds[1]("a")[0].string,tds[1]("a")[1].string,tds[1]("p")[0].string,tds[2].string,tds[3].string,tds[4].string])
# print("title=", soup.title)
print("省市=",tds[2].string)
# print("校名2=", tds[1]("a")[0].string)
print("ulist=",ulist)
def printUnivList(ulist, num):
tplt = "{0:^10} {1:{3}^10} {2:^10}"
# tplt = "{:^10} {:^6} {:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
# print("%s %s %s" %("排名","学校名称","总分"))
for i in range(num):
u = ulist[i]
# print("%s %s %s" %(u[0].strip(" "),u[1],u[4].strip(" "))) # 删除左边的空格
print(tplt.format(u[0].strip(" "),u[1],u[6].strip(" "), chr(12288)))
def main():
url = "https://www.shanghairanking.cn/rankings/bcur/2022.html"
uinfo = []
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) # 20 univs
main()
