聊聊消息队列(MQ)那些事



每年的双十一期间,各大电商平台流量暴增,同时,电商平台系统的负载压力也会很大。譬如订单支付的场景,每个订单支付成功后,服务器可能要完成扣减积分、扣减优惠券、扣减商品库存、发短信等一系列操作。单个用户请求,服务器处理起来并没有什么问题,但是,瞬时并发的多个请求到了服务器,数据库压力上来了,导致请求响应慢,甚至宕机。
为了解决这个问题,我们可能会想到,让数据库处理完一个请求后再处理下一个请求不就好了么。就这样,消息队列出来了。消息队列,又称为MQ(Message Queue),它实现了让多个请求以消息的形式排好队,让消息处理程序一个一个的处理,有效防止了高并发给服务器带来的压力。
消息队列应用场景
MQ典型的应用场景有异步、削峰、解耦三种。
异步
譬如说一个系统A,它有一个操作处理完自己的逻辑以后需要调用其他系统的接口,如下图:
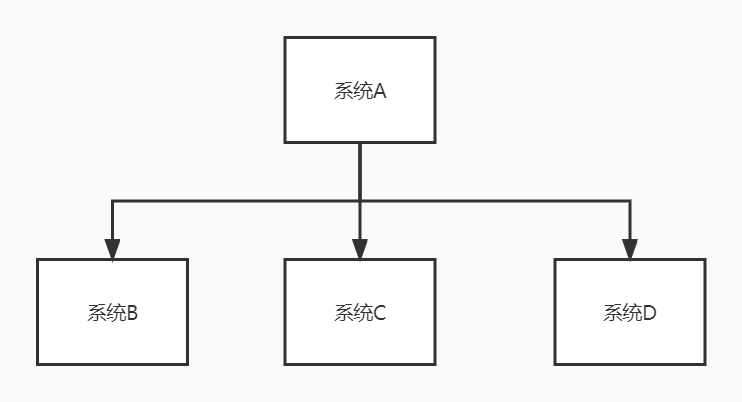
这时候,代码是这样:
public class SystemA {
@Resource
SystemBapi systemBapi;
@Resource
SystemCapi systemCapi;
@Resource
SystemDapi systemDapi;
public void doSomething() {
//产生一个id
long id = doSomethingAction();
//调用其他系统接口
systemBapi.doSomething(id);
systemCapi.doSomething(id);
systemDapi.doSomething(id);
}
}
上面的代码,系统A产生id的逻辑需要50ms,调用系统B的接口需要300ms,调用系统C的接口需要300ms,调用系统D的接口需要300ms。一个这样的操作就需要50+300+300+300=950ms。如果后面还要对接其他系统,这个操作的时间会更长。
如果调用其他系统接口实时性要求不高,那么,为了提高用户体验和吞吐量,调用其他系统接口的操作就可以交给MQ实现异步操作。如下图:

系统A执行完了以后,将id给到消息队列中,然后就直接返回了。
削峰
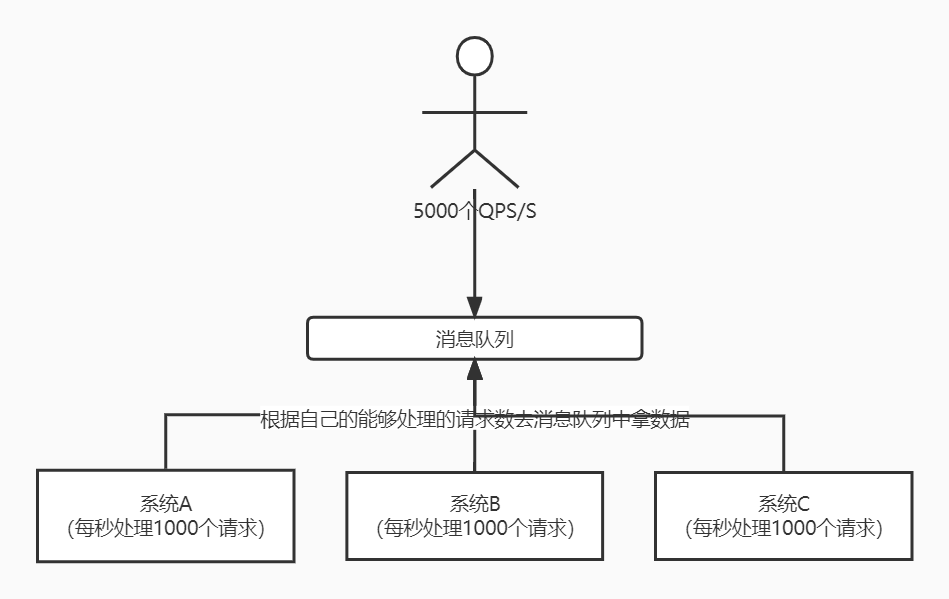
譬如有3台服务器组成集群,每台服务器的处理能力是1000个QPS/S,合起来就是3000个QPS/S。遇上了流量高峰,达到了5000个QPS/S,并发请求数量已经超过所有服务器总的处理能力,这时候就可以考虑利用MQ来控制并发数,以免服务器崩溃。
具体做法是所有请求先进入到MQ,然后每个服务器根据自己的能够处理的请求数去消费消息,也就是无论每秒多少个QPS,系统只处理能力范围内的请求数,剩下的请求等有资源再去处理,这就是“削峰填谷”,如下图:
解耦
解耦就是降低了消息生产者与消费者的耦合度。耦合度高,程序维护起来就会很麻烦。譬如,系统A产生了一个id后,需要把id交给系统B、系统C、系统D去处理。如果由系统A直接去调用其他系统接口,系统A的程序代码需要写上调用系统B、系统C、系统D接口的代码。如果某一天系统C说不需要处理系统A的id了,让系统A不要调用系统C的接口,那系统A要改代码。又某一天系统E说我要处理系统A的id,让系统A调用系统E的接口,系统A又得改代码。系统A的程序员这样子搞烦不烦?
系统A程序员有一天开窍了,把程序里所有调用外部系统的代码都屏蔽,弄了个MQ中间件,让系统A产生id以后就给到MQ。然后发个公告告诉所有其他系统的程序员,你们谁想要我这边产生的id你们自己去MQ拿,别来烦我。

这样一来,系统A跟其他系统就解耦了,代码也不用改来改去。
消息队列要注意的问题
问题一:可用性
MQ作为整个分布式架构的重要部件,如果MQ服务不可用,那整个系统都挂了。因此,MQ必须要支持集群。当下主流的MQ中间件都能够不同程度的支持集群,实现了MQ服务的高可用。
问题二:消息丢失
消息丢失有可能发生在生产者丢失消息、MQ本身丢失消息、消费者丢失消息3个方面。
-
生产者丢失消息
生产者丢失消息一般是在发送消息的时候出现异常(譬如网络异常),导致MQ无法接收到消息。这个问题可以采用本地消息表+回调通知+定时任务的方式解决。
就以系统A发送消息,系统B消费消息为例,具体解决方案如下:
1、系统A执行本地事务业务逻辑,并且往本地消息表插入一条数据(代表准备要发送的消息),消息状态为“未发送”。本地事务成功,提交保存本地数据,失败则回滚。
2、本地事务成功后,发送消息给MQ。
3、MQ接收到消息后,回调通知系统A,系统A把本地消息表对应的消息记录状态变为“已发送”。
4、定时任务轮询本地消息表,超过一定时间状态为“未发送”的消息重新发送给MQ。
5、定时任务处理超过一定次数一直发送不成功的消息告警,人工介入。
-
MQ丢失消息
消息成功发送到MQ,是先放到内存里的,如果还没来得及给消费者消费消息,MQ服务就挂了,就会丢失消息。MQ服务集群可以一定程度上解决这个问题,但集群中各节点的数据同步也需要一定时间,如果在同步数据之前MQ服务就挂了,消息也会丢失。还有一个方法就是MQ接收到消息的同时,把消息数据持久化到磁盘,这样,MQ服务恢复的时候就可以从磁盘获取数据重新给消费者消费。可能有人会问,那消息还没来得及持久化到磁盘MQ服务就挂了咋办?如果是这样,就可以用到前面说到的本地消息表,把本地消息表里的数据重新发一遍。
-
消费者丢失消息
消费者从MQ拉取消息,还没来得及处理消息,消费者服务器挂了。此时,可能造成消费者丢失消息。这种情况,可以让消费者处理完消息时给MQ一个确认消息来解决。如果MQ没有收到确认消息,就会有重试的机制,最终确保消息给到消费者消费。当然了,如果重试超过一定次数,就应该告警,人工介入。
问题三:重复消费
因为在网络延迟的情况下,消息重复发送的问题不可避免的发生。譬如,生产者发送消息的时候使用了重试机制,发送消息后由于网络原因没有收到MQ的确认信息,然后又去重新发送了一次消息。但其实MQ已经接到了消息,并返回了响应,只是因为网络原因导致生产者没有收到MQ的确认信息。这种情况下,生产者的消息重试机制就会继续就这个消息重新发送,从而导致同一条消息多次发送,这样消费者也会重复消费这条消息。当然,这只是列举了一种情况,实际上还有其他情况会导致消息被重复消费。
解决重复消费的关键就是在消费者端引入幂等性机制。什么是幂等性机制呢?我们可以把它理解成,假如一个接口被重复调用,依然可以保证数据的准确性。举个例子,比如每条消息都会有一个唯一的id,消费者处理完这个消息会存储这个id,如果处理消息之前能找到这个id,就说明这条消息已经处理过了,就不做处理并且返回给MQ一个确认信息。
消息队列中间件
为什么要用消息队列中间件?自己写不行吗?我们之所以要用中间件,是因为这些中间件已经解决了很多消息队列常见的问题(高可用、消息丢失、重复消费……),而且各种中间件都有各自的特性,已经做得非常成熟了,你确定你写的有这些中间件好用吗?
目前在市面上比较主流的MQ中间件主要有,ActiveMQ、RabbitMQ、Kafka、RocketMQ 等这几种。网上找来这几个中间件的对比,如下表:
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 时效性 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 功能特性 | MQ领域功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用 | MQ功能比较完备,扩展性佳 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 Kafka |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| broker端消息过滤 | 支持 | 不支持 | 不支持 | 可以支持Tag标签过滤和SQL表达式过滤 |
| 消息查询 | 支持 | 根据消息id查询 | 不支持 | 支持Message id或Key查询 |
| 消息回溯 | 支持 | 不支持 | 理论上可以支持时间或offset回溯,但是得修改代码。 | 支持按时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息。 |
| 路由逻辑 | 基于交换机,可配置复杂路由逻辑 | 根据topic | 根据topic,可以配置过滤消费 | |
| 持久化 | 内存、文件、数据库 | 队列基于内存,只能少量堆积 | 磁盘,大量堆积 | 磁盘,大量堆积 |
| 顺序消息 | 支持 | 不支持 | 支持 | 支持 |
| 社区活跃度 | 低 | 中 | 高 | 高 |
| 适用场景 | 主要场景就是解耦和异步调用,较少在大规模吞吐的场景中使用 | 数据量没有那么大,小公司 | 一般配合大数据类的系统来进行实时数据计算、日志采集等场景。 | 目前在阿里被广泛应用在订单、交易、充值、流计算、消息推送、日志流式处理、binglog分发消息等场景。 |
根据上表,我个人认为对性能要求比较高的,推荐选择RocketMQ,毕竟经历了多年阿里双十一极端并发的场景。如果是大数据领域的,可以选择Kafka。
