使用Pytorch进行多卡训练


当一块GPU不够用时,我们就需要使用多卡进行并行训练。其中多卡并行可分为数据并行和模型并行。具体区别如下图所示:
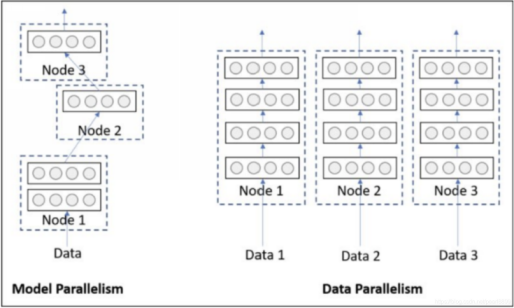
由于模型并行比较少用,这里只对数据并行进行记录。对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(DistributedDataParallel, DDP)。
在多卡训练的实现上,DP与DDP的思路是相似的:
1、每张卡都复制一个有相同参数的模型副本。
2、每次迭代,每张卡分别输入不同批次数据,分别计算梯度。
3、DP与DDP的主要不同在于接下来的多卡通信:
DP的多卡交互实现在一个进程之中,它将一张卡视为主卡,维护单独模型优化器。所有卡计算完梯度后,主卡汇聚其它卡的梯度进行平均并用优化器更新模型参数,再将模型参数更新至其它卡上。
DDP则分别为每张卡创建一个进程,每个进程相应的卡上都独立维护模型和优化器。在每次每张卡计算完梯度之后,进程之间以NCLL(NVIDIA GPU通信)为通信后端,使各卡获取其它卡的梯度。各卡对获取的梯度进行平均,然后执行后续的参数更新。由于每张卡上的模型与优化器参数在初始化时就保持一致,而每次迭代的平均梯度也保持一致,那么即使没有进行参数复制,所有卡的模型参数也是保持一致的。
Pytorch官方推荐我们使用DDP。DP经过我的实验,两块GPU甚至比一块还慢。当然不同模型可能有不同的结果。下面分别对DP和DDP进行记录。
DP
Pytorch的DP实现多GPU训练十分简单,只需在单GPU的基础上加一行代码即可。以下是一个DEMO的代码。
import torch
from torch import nn
from torch.optim import Adam
from torch.nn.parallel import DataParallel
class DEMO_model(nn.Module):
def __init__(self, in_size, out_size):
super().__init__()
self.fc = nn.Linear(in_size, out_size)
def forward(self, inp):
outp = self.fc(inp)
print(inp.shape, outp.device)
return outp
model = DEMO_model(10, 5).to("cuda")
model = DataParallel(model, device_ids=[0, 1]) # 额外加这一行
adam = Adam(model.parameters())
# 进行训练
for i in range(1):
x = torch.rand([128, 10]) # 获取训练数据,无需指定设备
y = model(x) # 自动均匀划分数据批量并分配至各GPU,输出结果y会聚集到GPU0中
loss = torch.norm(y)
loss.backward()
adam.step()
