HashMap面试相关


HashMap源码:
- 加载因子:loadFactory — 默认 0.75f
- 初始容量大小: capacity 默认 16, 最大限制 1<<30
- 扩容: 当数组元素的数量 > 初始容量大小 * 加载因子,就会扩容. 会调用rehash方法将数组长度扩容到之前的两倍.扩容的时候,会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能.
Jdk1.7和jdk1.8区别
- jdk1.7之前 采用的是 数组 + 链表的方式, 采用的是头插法,扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题
- jdk1.8之后 采用的是 数组 + 链表/红黑树的方式 当某个位置出现哈希冲突时,会将元素放到该位置的链表后面,当链表长度超过8时, 会尝试采用红黑树来存储, 若数组长度 若大于 64,链表长度 大于8会 将链表的所有节点都转换成红黑树,若数组长度 小于64,会扩容
Map get() 和 put()原理
- 1.8中put: put中调用putVal()方法
- 1)首先判断map中是否有数据,没有就执行resize方法(扩容也是通过这个方法)
- 2)如果要插入的键值对要存放的这个位置刚好没有元素,那么就把他封装成Node对象,放在这个位置上
- 3)如果这个元素的key和与要插入的一样,就替换一下
- 4)如果当前节点是TreeNode类型的数据,执行putTreeVal方法
-
get:
-
1)调用k的hashCode()计算出哈希值,并通过哈希算法转换成数组的下标.
-
2)通过上一步哈希算法转换成数组的下标后,通过数组快速定位到某个位置.如果这个位置上什么都没有,返回null如果有,则拿着K和单向链表上的每一个节点K进行equals,如果所有equals都返回false,则返回null若true,则返回该value.
-
resize方法: 两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容.
具体键值对在哈希表中的位置取决于该位运算: i = (n-1) & hash
-
热点问题:
为什么HashMap要树化?
本质上是因为安全问题.因为,在元素的存放过程中,如果一个对象哈希冲突,都被放到一个桶里,则会形成一个链表,而链表的查询是线性的会严重影响存取的性能.而现实情况中,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就会利用这些数据与服务器大量交互,导致服务器端cpu大量占用,这就构成了哈希碰撞拒绝服务攻击.
ps:用哈希碰撞发起拒绝服务攻击(DOS,Denial-Of-Service attack),常见的场景是攻击者可以事先构造大量相同哈希值的数据,然后以JSON数据的形式发送给服务器,服务器端在将其构建成为Java对象过程中,通常以Hashtable或HashMap等形式存储,哈希碰撞将导致哈希表发生严重退化,算法复杂度可能上升一个数据级,进而耗费大量CPU资源。
HashMap,HashTable,TreeMap,LinkedHashMap的区别
-
HashMap继承自AbstractMap类,而HashTable继承自Dictionary类,不过它们都同时实现了map,cloneable,serializable接口.存储的内容是基于 key-value的键值对映射,key不能重复,一个key只能映射一个value.HashSet的底层就是基于HashMap实现的.
-
HashTable的key,value都不能为null
HashMap key 和 value 都可以为null,但只能有一个key为null,可以有多个null的value
TreeMap 键值都不能为null -
一般情况下,选用HashMap,因为HashMap的键值对在取出时是随机的,依据key的hashCode和键的equals方法来存取数据,具有很快的访问速度,所以在map中插入,删除及索引元素时效率较高.而TreeMap的键值对在取出时是排过序的,所以效率低一点.
-
TreeMap是基于红黑树的一种提供顺序访问的map,与HashMap不同的是它的get,put,remove之类的操作都是o(log(n))的时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断.
-
LinkedHashMap适合需要输出的顺序和输入的顺序相同的情况
-
HashMap是线程不安全的,HashTable是线程安全的.所以HashTable的效率比不上HashMap
前者默认初始化数组大小为16,后者为11,扩容时,扩大两倍,后者扩大两倍+1
-
HashMap需要重新计算hash值,而hashTable直接使用对象的hashCode
HashMap在1.7和1.8之间的变化
- 1.7中采用数组+链表,1.8采用数组+链表/红黑树
- 1.7扩容时需要重新计算哈希值和索引位置,1.8并不重新计算哈希值,巧妙地采用和扩容后容量进行&操作来计算新的索引位置.
- 1.7采用头插法: 扩容时会改变链表中元素的原本顺序,以至于在并发场景下导致链表成环的问
- 1.8采用尾插法: 扩容时会保持链表原本的顺序,避免了链表成环的问题.
当两个对象的hashCode相同时会发生什么?
- hashCode相同,equals不一定为true,所以两个对象所在数组的下标相同,”碰撞”就此发生.会存储在数组该位置的链表(红黑树)中.
你知道hash的实现吗?为什么要这样实现?
-
1.8中,通过hashCode()的高16位异或低16位实现的
(h = k.hashCode()) ^ (h >>> 16)主要是从速度,功效和质量来考虑的,减少系统的开销,也不会因为高位没有参与下标的计算,从而引起碰撞
-
用异或运算符,保证了对象的hashCode的32位值只要有一位发生改变,整个hash()返回值就会改变,尽可能的减少碰撞
拉链法导致的链表过深问题为什么不用二叉树代替,而选择红黑树?为什么不一直使用红黑树?
- 红黑树是为了解决二叉查找树的缺陷,二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,同样会造成很深的问题),遍历查找会非常慢.
- 红黑树在插入新数据后会通过左旋,右旋或者变色操作来保持平衡,引入红黑树是为了查找数据快,解决链表查询深度的问题,红黑树属于平衡二叉树,尽管为了保持平衡会付出代价,但该代价损耗的资源相比遍历线性链表来说要少.所以,当长度大于8的时候,会使用红黑树.而为什么是8,是因为符合泊松分布,为8时资源损耗相对来说较少.
HashMap和CuncurrentHashMap的区别?
- ConcurrentHashMap类是java并发包java.util.concurrent中提供的一个线程安全且高效的HashMap实现.
- 1.7中ConcurrentHashMap采用分段锁(ReentrantLock + segment +hashEntry),相当于把一个HashMap分成多个段,每段分配一把锁,这样支持多线程访问.锁粒度:基于segment,包含多个HashEntry
- 1.8中采用CAS + synchronized + Node + 红黑树.锁粒度: Node.锁粒度降低了
- HashTable则使用synchronized关键字加锁
- 区别: ConcurrentHashMap键值对都不允许为null
ConcurrentHashMap简单介绍一下?
-
java.util.concurrent.ConcurrentHashMap属于JUC包下的一个集合类,可以实现线程安全.
-
1.8之前:
- 由多个Segment组合而成,Segment本身就相当于一个HashMap对象.同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点.
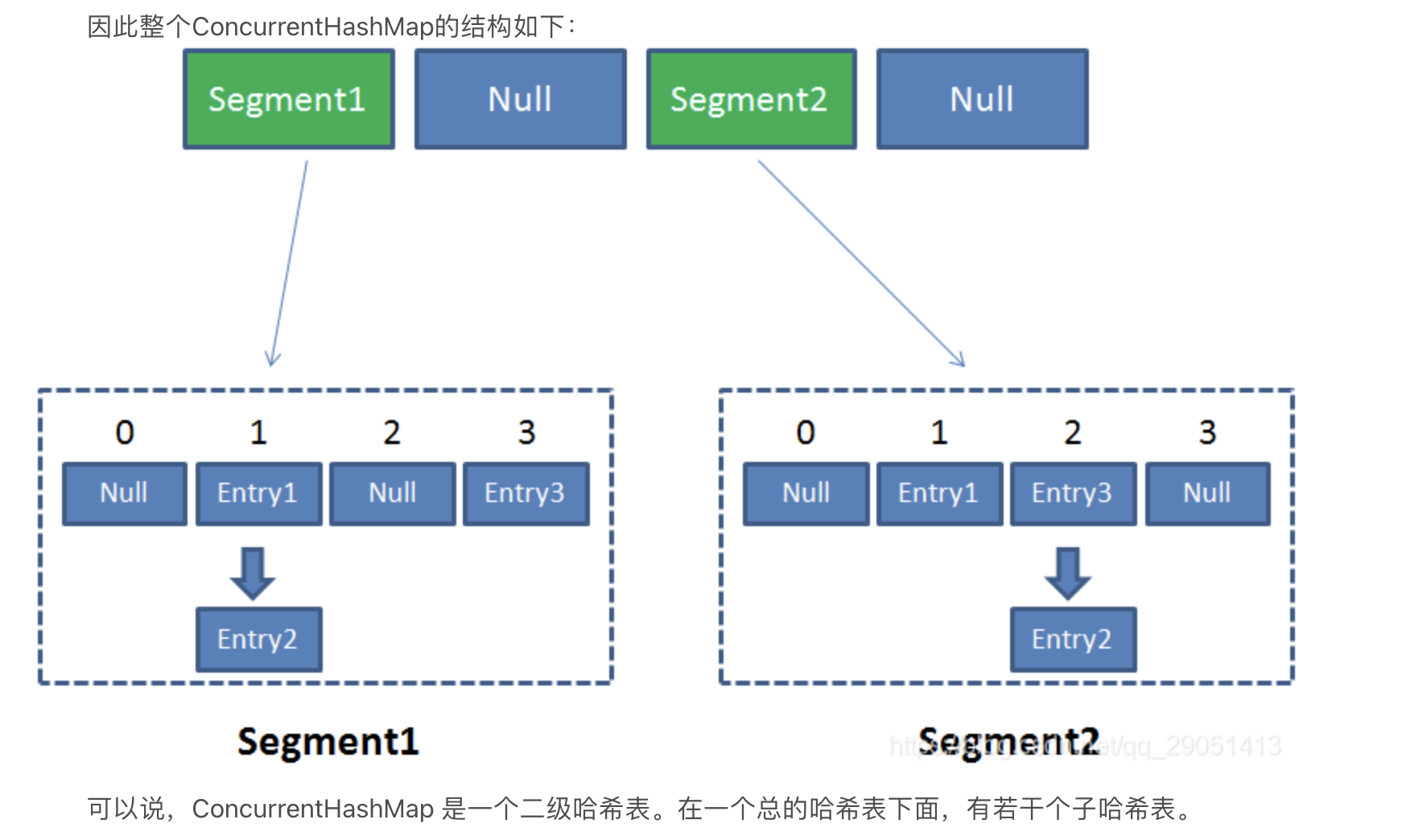
-
Put: 首先,会尝试获取锁,若获取失败,则利用scanAndLockForPut()自旋获取锁.如果重试的次数达到了MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功.接着,遍历该HashEntry,如果不为空则判断传入的key和当前遍历的key是否相等,相等则覆盖旧的value.为空,则需要新建一个HashEntry并加入到Segment中,同时会先判断是否需要扩容.
-
Get: key通过hash之后定位到具体的segment,再通过一次hash定位到具体元素上.
由于HashEntry中的value属性是用volatile关键字修饰的,保证了内存可见性,所以每次获取时都是最新值. 整个过程非常搞笑,不需要加锁.
- 由多个Segment组合而成,Segment本身就相当于一个HashMap对象.同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点.
- 1.8之后:
- 数组+链表 改为 数组+链表/红黑树,HashEntry改为Node
ConcurrentHashMap的key,value是否可以为null,为什么?
-
都不可以为null,为null时会抛出空指针异常.
ConcurrentHashMap是一个用于多线程并发场景下的并发容器(map),在多线程环境下执行增删改查方法要保证线程安全性.
-
不能为null,因为会产生二义性问题: 当我们用get方法去获取一个value为null的时候,可能会没有这个key,也可能会有这个key,只不过value为null.
-
HashMap如何解决二义性问题
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}- 如果存在key为null的元素(key = null对应的hash值为0),getNode获取到值不为null
- 如果不存在key为null的元素,此时hash值=0对应的下标元素为null,即getNode获取到的值为null
-
ConcurrentHashMap为什么不能解决二义性问题
- 因为ConcurrentHashMap是一个用在多线程并发的map容器,不能put null 是因为无法分辨是key没找到null,还是有key的值为null.这在多线程里没法保证会不会有其他线程修改为null键和null值的情况,所以不让put null.
参考文档
-
HashMap详解
-
面试:HashMap夺命二十一问
-
深入浅出ConcurrentHashMap
-
ConcurrentHashMap(1.8)讲解及常见面试题
