day21-


Java集合04
9.Set接口方法
-
Set接口基本介绍
- 无序(添加和取出的顺序不一致),没有索引
- 不允许重复元素,所以最多只有一个null
- JDK API中接口的实现类有:

-
Set接口的常用方法:和List接口一样,Set接口也是Collection的子接口,因此,常用方法和Collection接口一样。
-
Set接口的遍历方式:同Collection的遍历方式一样,因为Set是Collection的子接口所以:
- 可以使用迭代器
- 增强for循环
- 不能使用索引的方式来获取

例子1:以Set接口的实现类HashSet来讲解Set的方法
1.set接口的实现类的对象(set实现类对象),不能存放重复的数据,且最多只能添加一个null
2.set接口对象存放数据是无序的(即添加对象顺序和取出的对象顺序不一致)
3.注意:但是取出的顺序是固定的
package li.collections.set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
@SuppressWarnings("all")
public class SetMethod {
public static void main(String[] args) {
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");
set.add("jack");
set.add("marry");
set.add(null);
set.add(null);
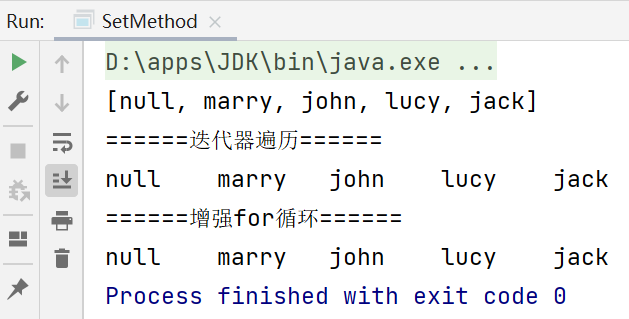
System.out.println(set);//取出的顺序是一致的:[null, marry, john, lucy, jack]
//遍历
//1.使用迭代器
Iterator iterator = set.iterator();
System.out.println("======迭代器遍历======");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.print(obj+" ");
}
//2.增强for循环
System.out.println("
"+"======增强for循环======");
for (Object o:set) {
System.out.print(o+" ");
}
//set接口对象不能使用通过索引来获取,因此没有get方法
}
}
10.HashSet
- HashSet实现了接口Set
- HashSet实际上是HashMap

- 可以存放null值,但只能有一个null
- HashSet 不保证元素是有序的,取决于hash后,再确定索引的结果
- 不能有重复元素/对象
例子1:不允许重复元素
package li.collections.set;
import java.util.HashSet;
import java.util.Set;
@SuppressWarnings("all")
public class HasSet_ {
public static void main(String[] args) {
Set hashSet = new HashSet();
//1.HashSet可以存放null,但是只能存放一个null,即不允许重复元素
hashSet.add(null);
hashSet.add(null);
System.out.println(hashSet);//[null]
}
}
例子2:
package li.collections.set;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSet01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
//1.在执行add方法后会返回一个boolean值,添加成功返回true,失败则返回false
System.out.println(hashSet.add("john"));//true
System.out.println(hashSet.add("lucy"));//true
System.out.println(hashSet.add("john"));//false,可以看出这里添加失败了,不允许重复元素
System.out.println(hashSet.add("jack"));//true
System.out.println(hashSet.add("rose"));//true
//2.可以通过remove()指定删除哪个对象
hashSet.remove("john");
System.out.println(hashSet);//[rose, lucy, jack]
}
}
10.1怎么理解不能添加相同的元素/数据?
例子:
package li.collections.set;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSet01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("lucy");//添加成功
hashSet.add("lucy");//添加失败
hashSet.add("lucy");//添加失败
hashSet.add(new Dog("tom"));//添加成功
hashSet.add(new Dog("tom"));//添加成功
System.out.println(hashSet);//[Dog{name="tom"}, Dog{name="tom"}, lucy]
//!!!经典面试题:
hashSet.add(new String("jackcheng"));//添加成功
hashSet.add(new String("jackcheng"));//添加失败,为什么呢?
System.out.println(hashSet);//[jackcheng, Dog{name="tom"}, Dog{name="tom"}, lucy]
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name="" + name + """ +
"}";
}
}
为什么相同的两个 hashSet.add(new Dog("tom")); hashSet.add(new Dog("tom"));语句可以添加成功,而却添加失败呢?原因在于HashSet的底层机制
hashSet.add(new String("jackcheng"));//添加成功
hashSet.add(new String("jackcheng"));//添加失败,为什么呢?
10.2HashSet的底层扩容机制
HashSet底层是HashMap,HashMap底层是数组+链表+红黑树
说明:
- HashSet底层是HashMap第一次添加时,table数组扩容到16,临界值(threshold)是16*加载因子(loadFactor,0.75)=12;如果table数组容量使用到了临界值12,就会扩容到16 * 2=32,新的临界值就是32 * 0 .75=24,依此类推(两倍扩容)
注意:这里的容量计算的不仅仅是table数组上的容量,链表上的容量也算。即只要增加了一个元素,使用的容量就+1
例如:当一个table表的数组某个索引位置上存储了一个值,而这个值后面的链表存储了7个值,加起来就是8,那么在数组长度没有超过64时,再加入一个值,数组就会进行两倍扩容
-
添加一个元素时,先得到一个hash值–会转成–索引值
-
找到存储数据表table,看这个索引位置是否已经存放有元素
3.1 如果没有则直接加入
3.2 如果有,则调用equals()比较,如果相同就放弃添加;如果不相同则添加到最后
-
在jdk8中,如果一条链表的元素个数 >= TREEIFY_THRESHOLD (默认为8),并且table数组的大小 >= MIN_TREEIFY_CAPACITY (默认为64)就会进行树化(红黑树),否则仍然采用数组扩容机制
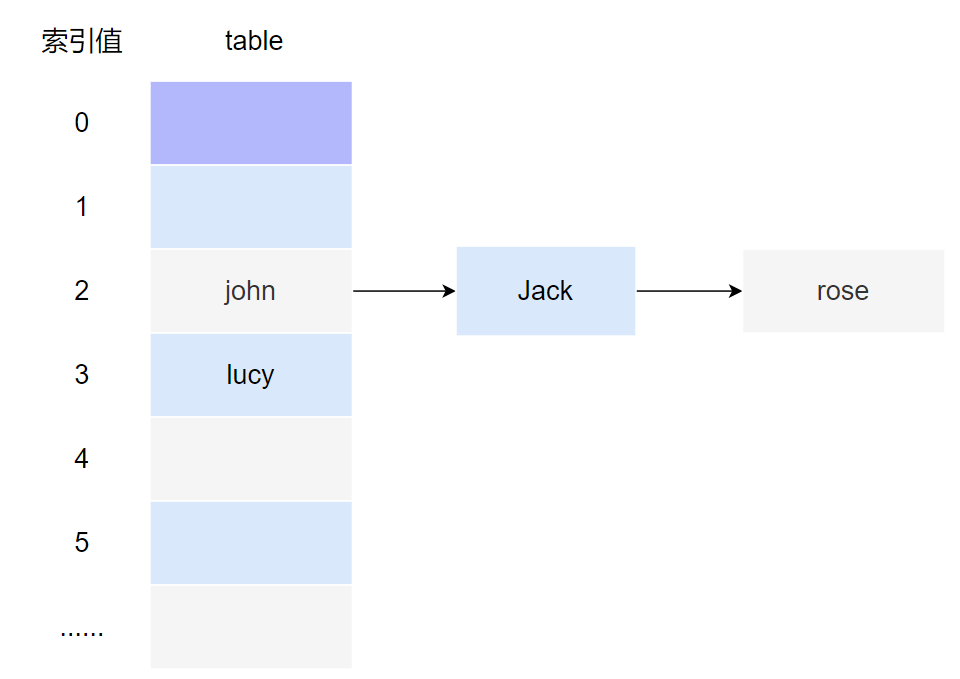
例子:模拟链表
package li.collections.set;
public class HashSetStructure {
public static void main(String[] args) {
//模拟一个HashSet的底层(即HashMap的底层结构)
//1.创建一个数组,数组的类型是Node
Node[] table = new Node[16];
System.out.println(table);
//2.创建结点
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;//将Jack结点挂载到john后面
Node rose = new Node("rose", null);
jack.next = rose;//将rose结点挂载到jack后面
Node lucy = new Node("lucy", null);
table[3] = lucy;//把lucy存放到table表索引为3 的位置
System.out.println(table);
}
}
class Node {//结点,用于存放数组,可以指向下一个节点从而形成链表
Object item;//存放数据
Node next;//指向下一个节点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
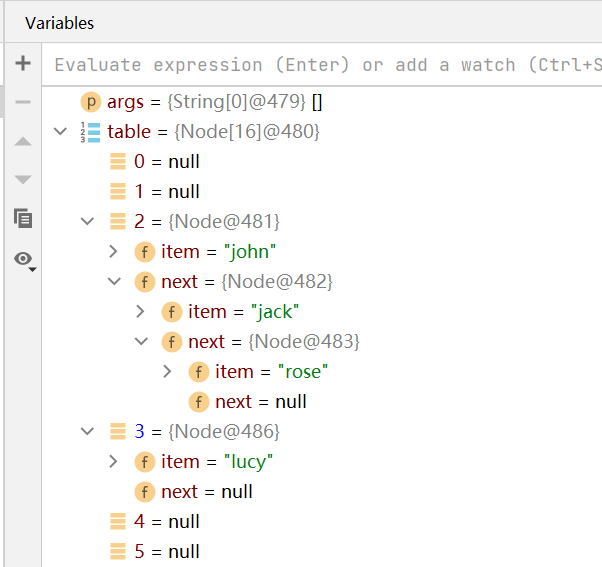
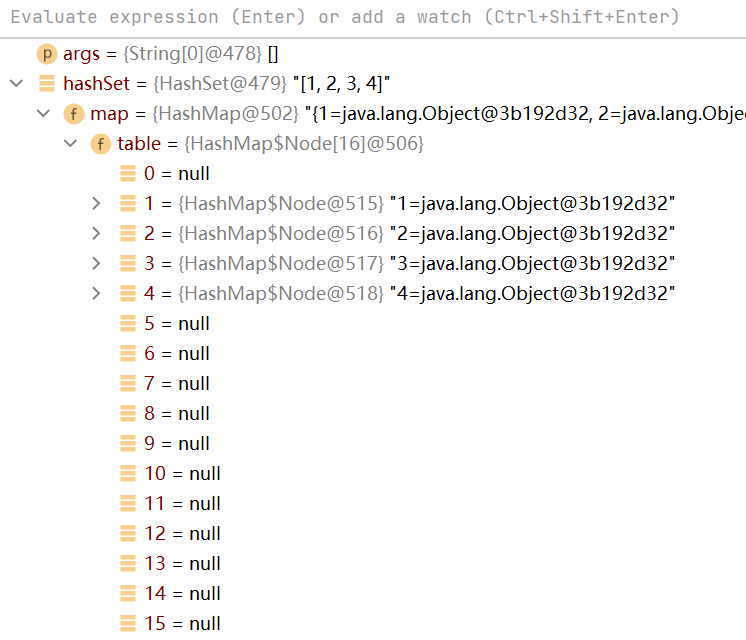
例子2:HashSet的两倍扩容机制
- 如图,HashSet第一次添加数据,table数组的长度为16
-
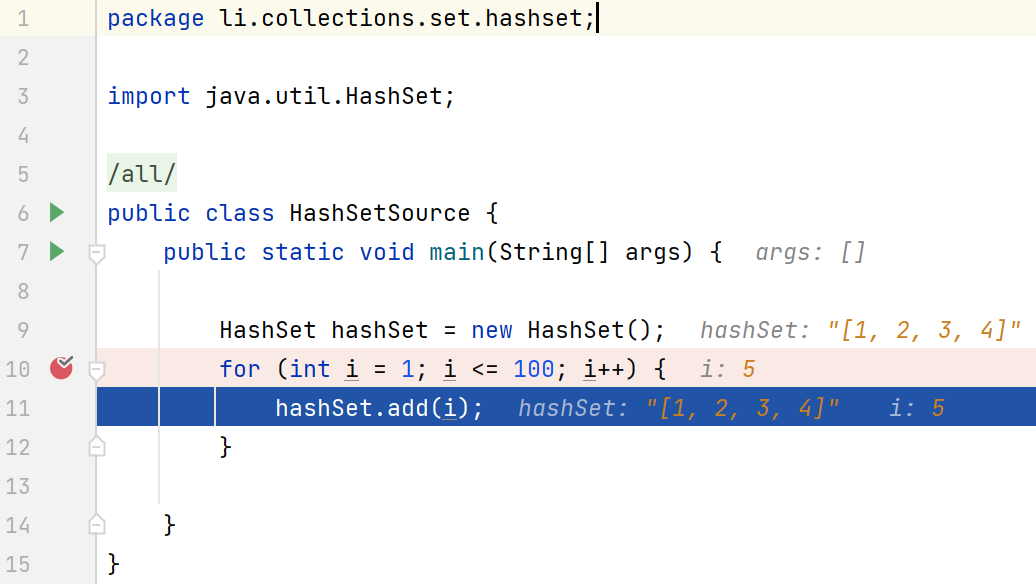
在数组容量使用到12(临界值) 时,会进行一个两倍的扩容(12*0.75=32)
例子3:HashSet的树化
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 1; i <=12 ; i++) {
hashSet.add(new A(i));
}
System.out.println(hashSet);
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode(){//重写hashCode方法
return 100;
}
}
如上所示,将hashCode方法重写,使其返回相同的哈希值,这样可以快速地使table链表的值达到8以上
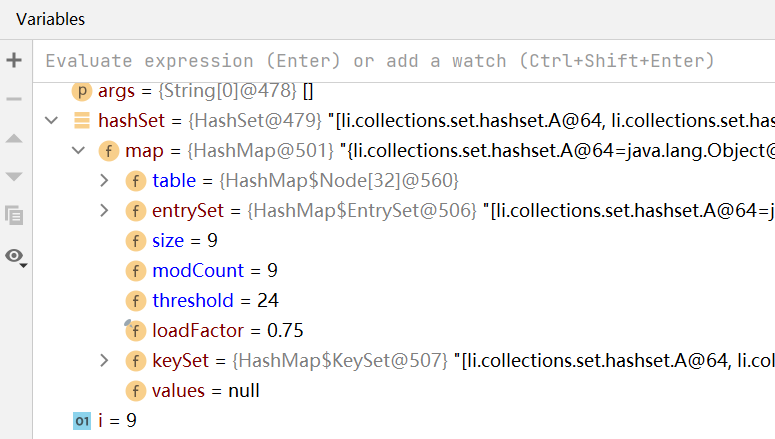
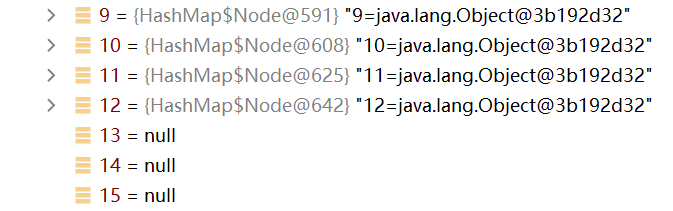
如上图所示,当链表数量到达8之后,table的容量进行两倍扩容,变成32,临界值为24

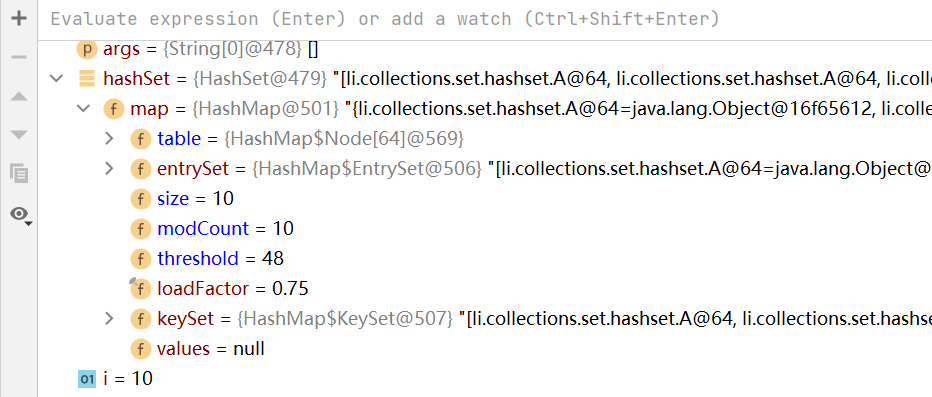
如上图,当链表数量到达9之后,table的容量进行两倍扩容,变成64,临界值为48
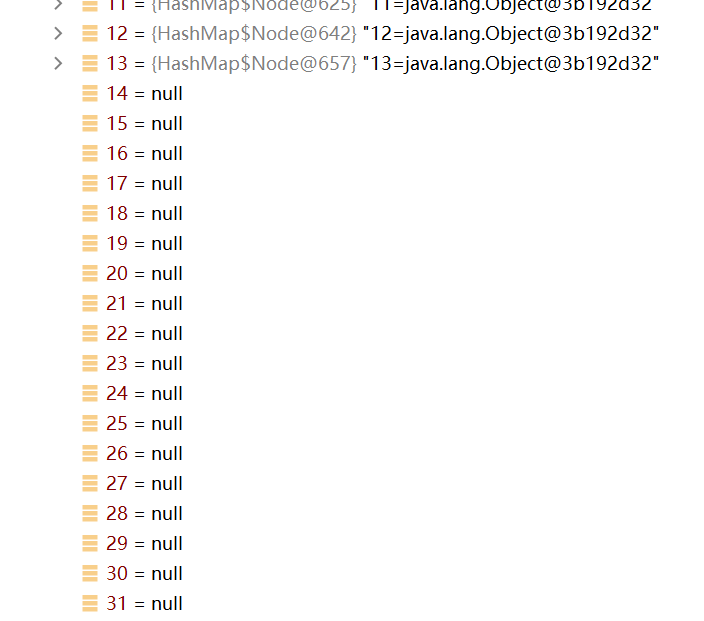
如下所示:当链表数量到达10之后,table此刻符合树化的条件(长度>=64,链表长度>=8),将链表转变为红黑树,不再进行扩容

例子4:验证—>扩容 需要的使用容量计算的不仅仅是数组上的容量,链表上的容量也算
如下,重写hashCode()方法,让 其快速在某一个链表上添加
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 1; i <=7 ; i++) {//在table的某一条链表上添加了7个A个对象
hashSet.add(new A(i));
}
for (int i = 1; i <=7 ; i++) {//在table的另外一条链表上添加了7个B对象
hashSet.add(new B(i));
}
System.out.println(hashSet);
}
}
class B{
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode(){//重写hashCode方法
return 200;
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode(){//重写hashCode方法
return 100;
}
}
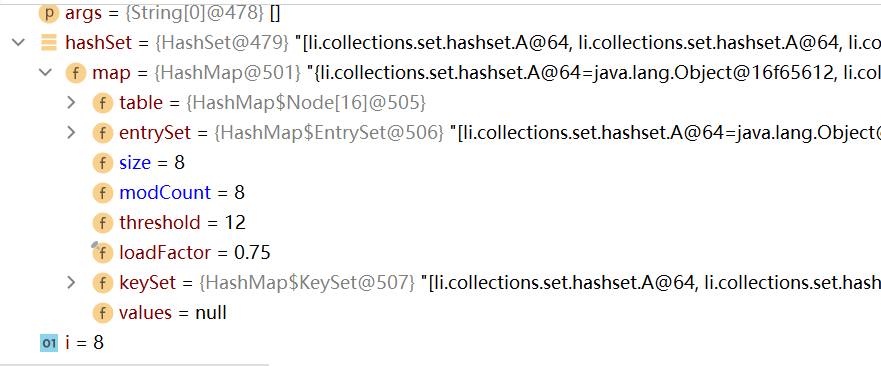
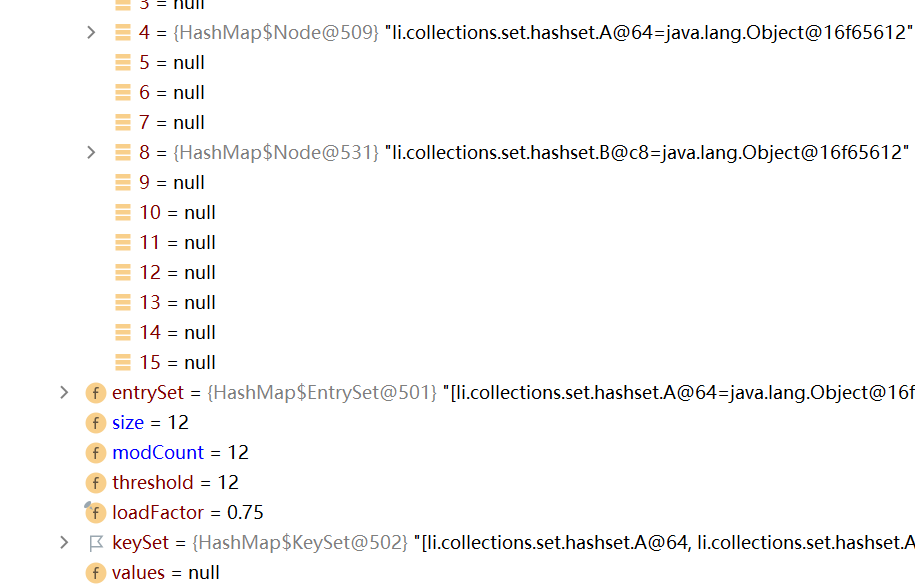
如下图,在第二个循环语句上打上断点,可以看到在table表中有两个链表。此时,在索引4的位置上存放了7个A对象,在索引8的位置上存放了5个对象,此时整个数组的长度为16
接下来再添加一个数据,即此时数组上的数据+链表上的数据总量为13,超过临界值时4,可以看到table数组进行了扩容(64)
说明扩容临界值计算的是添加数据的总个数,而非单指table表上的数据个数
10.3HashSet源码解读
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set="+hashSet);
}
}
-
HashSet hashSet = new HashSet();首先new HashSet()会调用HashSet构造器
-
hashSet.add("java");第一次调用add()方法:
-
add()方法又调用了put()方法:

其中,key就是传递的参数:java,而value则是add()方法的PRESENT,PRESENT是一个用于占位的Object对象,被设置为静态且是常量

-
点击hash(key)方法,查看:

可以看到,如果传入的参数key为空的话,就返回0;如果不为空,则求出 key 的 hashCode 值,然后将hashCode 值右移16位并且与原来的 hashCode 值进行 ^(按位异或) 操作,并返回这个哈希值
-
回到上一层,点击进入putVal()方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {// Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量 //这里定义的tablejiushi HashMap的一个数组,类型是Node[]数组 if ((tab = table) == null || (n = tab.length) == 0)//if 语句表示,如果当前table是null,或者大小=0,则进行第一次扩容,扩容到16个空间 n = (tab = resize()).length;//如果为第一次扩容,此时初始的table已经变成容量为16的数组 /* 1.根据key,得到hash 去计算key应该放到table表的哪个索引位置,并且把这个未知的对象赋给赋值变量p 2.再判断p是否为空 2.1如果p为空,表示该位置还没存放元素,就创建一个Node (key="java", value=PRESENT)并把数 据放在该位置--table[i]=newNode(hash, key, value, null); */ if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //2.2如果不为空,就会进入else语句 Node<K,V> e; K k;//定义辅助变量 /*这里的p指向当前索引所在的对象(由上面的p = tab[i = (n - 1) & hash])计算出索引位置),如 果当前索引位置对应链表的第一个元素的哈希值 和 准备添加的key的哈希值 一样, 并且 满足下面两个条件之一: 1.准备加入的key 和 p指向的Node节点 的key 是同一个对象:(k = p.key) == key 2.p指向的Node节点的key 的equals()和准备加入的key比较后相同并且key不等于null:(key != null && key.equals(k)) 就不能加入 */ if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //再判断p是否是一颗红黑树 //如果是红黑树,就调用putTreeVal()方法来进行添加 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //如果table对应索引位置已经是一个链表了,就使用for循环依次比较 //(1)依次和该链表的每个元素都比较后 都不相同,就则将数据加入到该链表的最后 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) {//先赋值再判断 p.next = newNode(hash, key, value, null); //注意:把元素添加到链表之后立即 判断该链表是否已经达到8个节点,如果已经达到则 调用 treeifyBin()对当前链表进行树化(转成红黑树) //在转成红黑树时 还要进行一个判断: //如果该table数组的为空或者大小小于64,则对table数组进行扩容 //如果上面条件不成立,即数组大小大于等于64且链表数量达到8个,就转成红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //(2)如果在依次和该链表的每个元素比较的过程中发现如果有相同情况,就直接break if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e;//在上面for循环条件已经把p.next赋值给e了,这里e又赋值给p 其实就是将p指针指 //向p.next,然后再进行新一轮的判断,如此循环,直到有满足上面if语句的条件为止 } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
