动态规划的引入

动态规划的引入
动态规划(Dynamic Programming,DP)是运筹学的一个分支,是求解决策过程最优化的过程。20世纪50年代初,美国数学家贝尔曼(R.Bellman)等人在研究多阶段决策过程的优化问题时,提出了著名的最优化原理,从而创立了动态规划。动态规划的应用极其广泛,包括工程技术、经济、工业生产、军事以及自动化控制等领域,并在背包问题、生产经营问题、资金管理问题、资源分配问题、最短路径问题和复杂系统可靠性问题等中取得了显著的效果。
——百度百科
动态规划与分治法相似,都是通过组合子问题来求解原问题。根据算法导论,Programming 译作“表格法”而不是“编写程序”,“动态规划”这个名字网络上有段子说是用来讨要经费的。
包含如下特征:
- 阶段 问题被划分为若干阶段,每阶段受先前阶段影响
- 状态 描述该阶段特定子问题的若干变量
- 决策 从一个状态演变到下一阶段某个状态的选择
- 最优子结构 一个最优化策略的子策略总是最优的
- 无后效性 已经求解的子问题,不会再受到后续决策的影响
OI 中 DP 的含义被极大地扩展了,下面提取两大核心特征
-
状态 一个含义清晰且独立 (即无后效性) 的子问题 $I $
▶ 使用 (f_I) 表示子问题 $ I$ 的答案
▶ 可能需要引入辅助子问题 $g_J, h_K, · · · $
-
转移 答案 (f_I) 通过状态转移方程由其它子问题共同计算得到
▶ 以状态为点,转移为边,构成有向无环图 (DAG)
▶ 边界条件与平凡子问题
▶ 解空间中的任意元素都被恰当考虑
如何理解最后一句话?按照问题类型分类
- 最优化 (k-优) 最优解能被考虑到,这依赖于最优子结构
- 计数 (概率, 期望) 计数对象 (事件) 能被不重不漏地处理
使用动态规划需要满足以下性质:
1.最优子结构性质。动态规划下一阶段的最优解应该能由前面已经算出的各阶段的最优解导出。
举个简单的例子。下面是一个地图,我们要找一条从左下角(起点)到右上角(终点)、只向右和向上走的路径。

如果要让路径经过的数字总和最大,那么最优路径是下面这条:
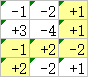
可以验证,对于最优路径上的任意一点,最优路径从起点到该点的部分,也正是从起点到该点的所有路径中数字总和最大的那一条。这就叫「满足最优子结构」。
现在换一个「最优」的标准,要求路径经过的数字总和的绝对值最小。那么最优路径是下面这条:
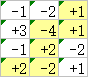
但是,对于最优路径上 -4 这个点,最优路径从起点到该点的部分,却不是从起点到该点的所有路径中,数字总和的绝对值最小的那一条,因为下面这条路径上数字总和的绝对值更小:
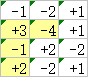
这就叫「不满足最优子结构」。
常见的最优化问题,问法一般都是「最大」「最小」,不太会出现「绝对值最小」这种奇葩的最优化标准。而问「最大」「最小」的问题,一般都是满足最优子结构的。 (栗子来自知乎 作者:王赟 Maigo)
2.无后效性。动态规划要求已经求解出的子问题不能受后续阶段的影响,也就是说,动态规划时对于状态空间的遍历应该构成一个有向无环图。
例如CSP-J 2020 方格取数 本题可以向上向下走,如果直接设计 (f(i, j)) 的状态表示走到格子 ((i, j)),那么如下图,状态转移形成环形,会产生后效性。
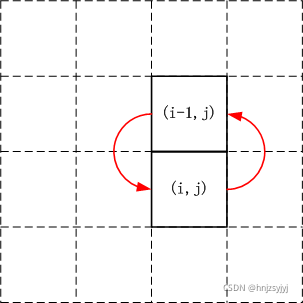
此时进行动态规划时就要设计一个无后效性的状态,如在原状态 (f(i, j)) 的基础上加一维表示方向。
3.子问题重叠。动态规划之所以优于爆搜,就是因为它以空间换时间的形式记录了前面所有状态的最优解。
状态、阶段和决策则是动态规划的三要素。动态规划将相同的计算作用在各阶段的同类子问题,这种计算被称为状态转移方程,其实也就是决策,将当前状态转移到下一状态或更新下一状态,或是根据前面的状态计算当前状态。
一般都是通过数字三角形引入:
Number Triangles
题目描述
观察下面的数字金字塔。
写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大。每一步可以走到左下方的点也可以到达右下方的点。
7 3 8 8 1 0 2 7 4 4 4 5 2 6 5在上面的样例中,从 (7 o 3 o 8 o 7 o 5) 的路径产生了最大
输入格式
第一个行一个正整数 (r) ,表示行的数目。
后面每行为这个数字金字塔特定行包含的整数。
输出格式
单独的一行,包含那个可能得到的最大的和。
样例 #1
样例输入 #1
5 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5样例输出 #1
30【数据范围】 对于 (100\%) 的数据,(1le r le 1000),所有输入在 ([0,100]) 范围内。
方法一:递归
int solve(int i, int j) {
return a[i][j] + (i == n ? 0 : max(solve(i + 1, j), solve(i + 1, j + 1)));
}
如果数据范围很小,可以考虑爆搜,所有路径条数为 (2^{n – 1}) ,所以时间复杂度为 (Theta(2^n)) ,无法接受。
方法二:递推
时间复杂度 (Theta(n^2))
#include<bits/stdc++.h>
using namespace std;
int a[1001][1001];
int main() {
int n = 0;
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j <= i; j++)
cin >> f[i][j];
for (int i = n - 2; i >= 0; i--)
for (int j = 0; j <= i; j++)
f[i][j] += max(f[i + 1][j], f[i + 1][j + 1]);
cout << f[0][0];
}
方法三:记忆化搜索
我们画出来方法一的搜索树:
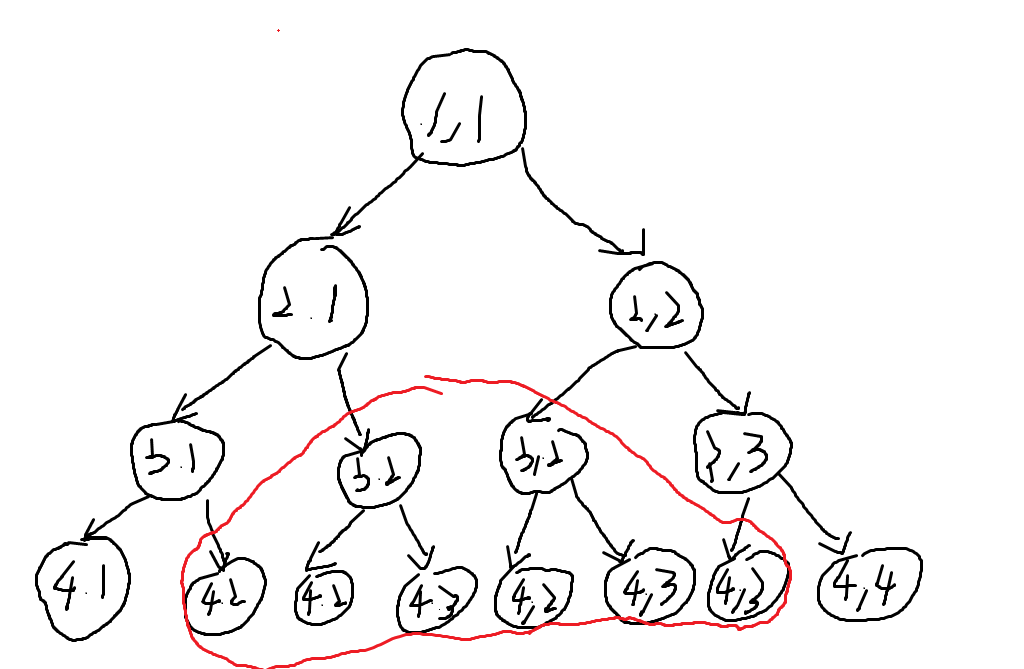
用红色圈起来的地方显然是重复计算了,可以用一个数组来记录搜过的状态,如果再次搜到已搜过的状态,就直接返回记录的值,这样没有了重复搜索,时间复杂度是 (Theta(n^2)).
memset(f, -1, sizeof(f));
int solve(int i, int j) {
if (f[i][j] >= 0) return f[i][j];
return f[i][j] = a[i][j] + (i == n ? 0 :
max(solve(i + 1, j), solve(i + 1, j + 1)));
}
