python爬虫爬取博客园


python 爬取 云海天 接 蚂蚁学pythonP5生产者消费者爬虫数据重复问题
-
先看访问地址
-
访问地址是
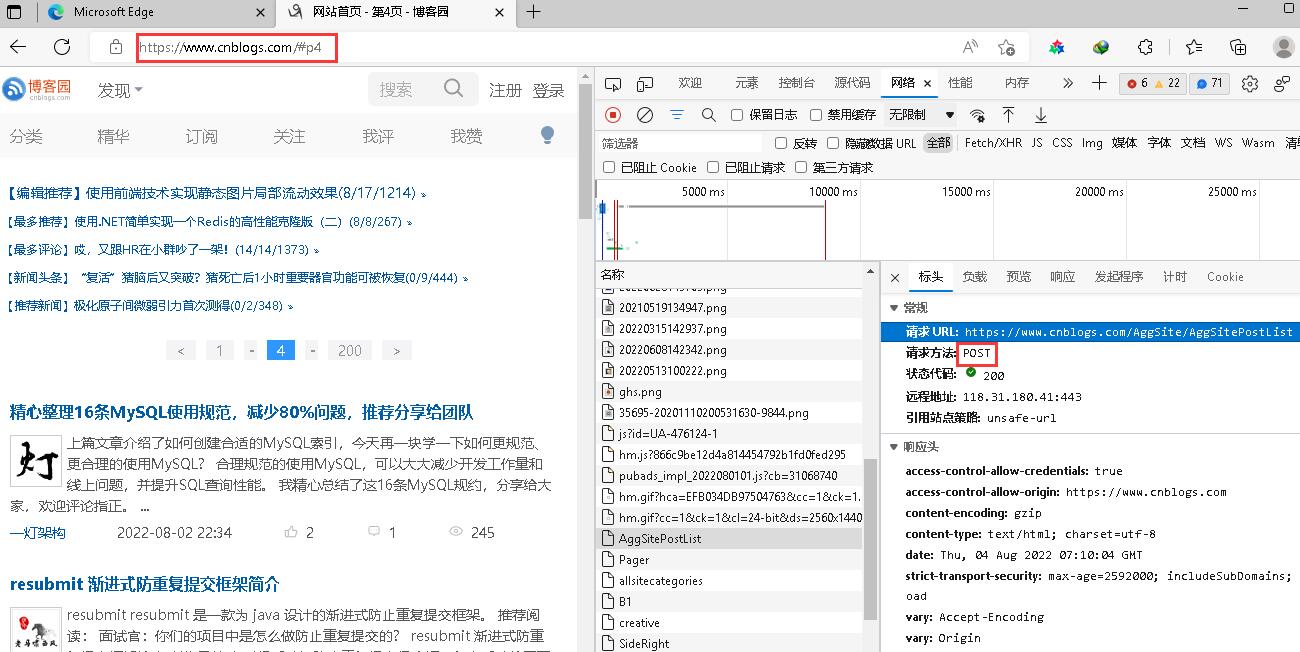
https://www.cnblogs.com/#p2但是实际访问地址是https://www.cnblogs.com说明其中存在猫腻;像这种我们给定指定页码,按理应该是 post 请求才对;于是乎 往下看了几个连接
-
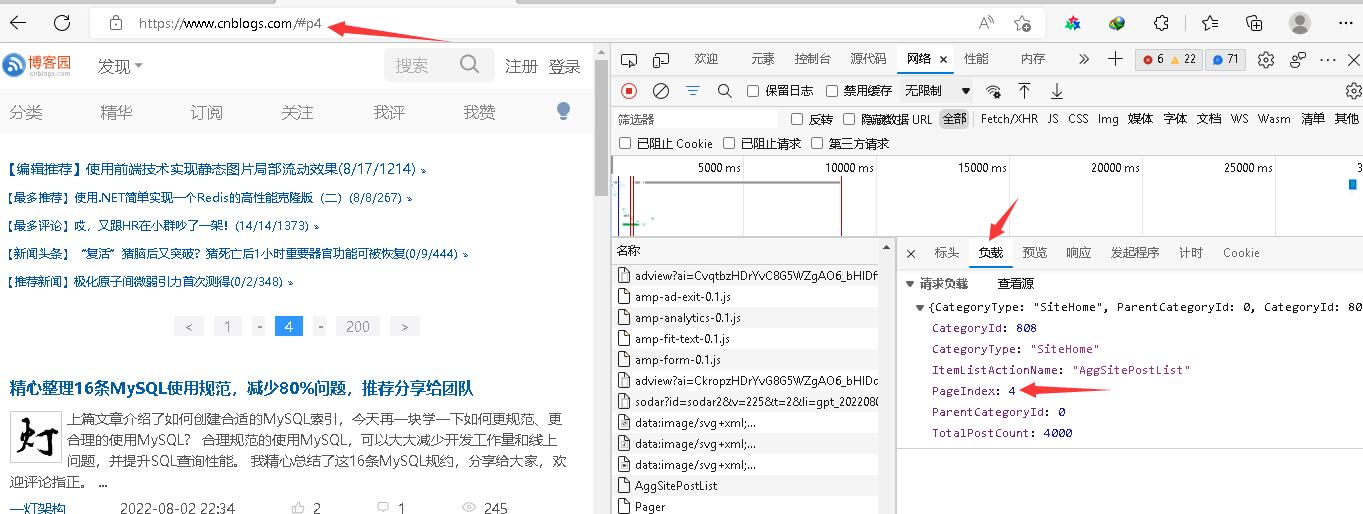
然后再看一下payload 发现这个post 请求 才是我们想要的链接 其中
PageIndex就是我们要设置的页数
-
-
代码撸起来
# Author: Lovyya # File : blog_spider import requests import json from bs4 import BeautifulSoup import re # 这个是为和老师的urls一致性 匹配urls里面的数字 rule = re.compile("d+") urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 31)] # pos请求网址 url = "https://www.cnblogs.com/AggSite/AggSitePostList" headers = { "content-type": "application/json", "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30" } def craw(urls): #idx 是"xxx.xxxx.xxx/#p{num}" 里面的num 这样写可以不用改 后面生产者消费者的代码 idx = rule.findall(urls)[0] # payload参数 只需要更改 idx 就行 payload = { "CategoryType": "SiteHome", "ParentCategoryId": 0, "CategoryId": 808, "PageIndex": idx, "TotalPostCount": 4000, "ItemListActionName": "AggSitePostList" } r = requests.post(url, data=json.dumps(payload), headers=headers) return r.text def parse(html): # post-item-title soup = BeautifulSoup(html, "html.parser") links = soup.find_all("a", class_="post-item-title") return [(link["href"], link.get_text()) for link in links] if __name__ == "__main__": for res in parse(craw(urls[2])): print(res)
