Kafka学习(三) 主题、分区与副本

主题、分区与副本
基本概念
主题、分区和副本的关系
主题是一个逻辑概念,代表了一类消息,实际工作中我们使用主题来区分业务,而主题之下并不是消息,而是分区,分区是一个物理概念,它是磁盘上的一个目录,目录中是保存消息的日志段文件。分区的目的是为了提高吞吐量,实现主题的负载均衡,一个主题至少有一个分区;而故障转移这个功能就放在了副本上,一个分区至少有一个副本,一个分区的所有副本原则上其数据是一致的且分布在不同的broker上,这样其中某一个broker故障那么其他的broker可以继续提供针对该分区的数据读写。
主题的名称是用户自己设定,分区名称是主题名称-分区编号,其中分区编号从0开始而且用户不可能自己设置。副本数量由用户设置。前面说过分区是存放消息的物理文件,那么消息也会被分配一个序列号,该序列号从0开始单调递增。
副本的类型
上面我们知道副本的作用是防止数据丢失,那么当有多个副本的时候这些副本都提供服务么?在Kafka的机制里副本并不都对外提供服务,它分为两类:Leader和Follower。前者对外提供读写服务后者只被动的从Leader副本同步数据。所以通过这里我们就可以回答一个问题就是3台Kafka集群,所有服务器都是活跃的不存在主从之分,服务器是否对外提供读写服务完全取决于所持有的副本类型,如果是Leader则提供,如果是Follower则不提供。
Kafka会尽量保证所有副本不在同一台机器上,但是如果副本数量大于集群机器数量那么就无法保证了。

上面这个主题就是3个分区,每个分区有3个副本。横向来看就是
Partition:0 这个分区当前的Leader副本在Broker.id为0的机器上
Replicas:1,0,2 表示副本有3个,以及这些副本都在哪些broker上
Isr:1,0,2 表示该集合中的所有副本的数据都与Leader副本保持同步状态。意味着只要Isr中存在一个活着的副本那么生产者已提交的数据就不会丢失,如果Isr中的某些副本落后Leader副本那么该落后的副本就会被移出。
副本与ISR
我们知道副本就是备份,Kafka会尽量把分区的副本均衡的放在不同broker上,并从中挑选一个作为Leader副本来对外提供读写服务,那么其他的就是Follower副本,而这些Follower副本保持与Leader副本的数据同步。
为什么Kafka只能让Leader副本提供读写操作呢?因为这样可以实现所写即所得,都是从Leader副本读写,所以写入数据后,消费者就可以马上读取;另外就是单调读,尤其是在副本数量多的时候,不会出现某些副本有这个数据,某些副本没有。所以这就是只让Leader副本提供读写操作的好处。
假如当前的Leader副本所在主机宕机,那么Kafka集群就要从剩余的Follower副本中重新挑选一个副本作为新的Leader副本,那么显然不是所有的Follower副本都具有竞选资格,如果某些Follower副本数据落后太多那么它们则不能成为Leader副本。所以这就有了ISR的概念。
ISR就是Kafka动态维护的一组同步副本集合,每个主题的分区都有自己的ISR列表,ISR中的所有副本都与Leader保持同步状态,而且Leader副本也在ISR列表中,只有在ISR列表中的副本才有这个被选中为Leader。

不过这里有人可能会糊涂,broker的id是从0、1、2,这里的Isr也是0、1、2这三个数字,那么Replicas和Isr中的数字表示的是broker的id呢还是分区的编号。下面我们修改一下集群中的broker的id,不过这种操作在线上可不建议使用。我们要把log.dirs目录中的数据删除,然后修改配置文件,然后再启动。
我们这里建立一个新的主题叫做TestBBB

可以看到无论是Replicas还是Isr显示的都是broker的id,而不是分区编号。下面我们说一下ISR是怎么同步的呢?
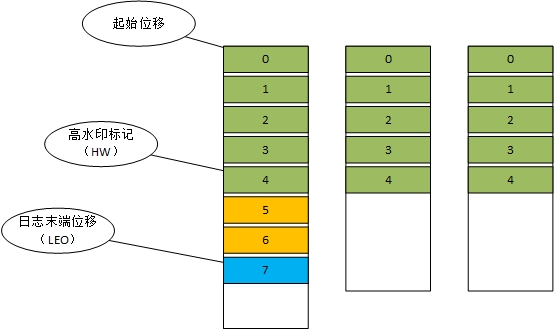
起始位移:表示副本中第一条消息的位置
高水位标记:表示副本最新一条被提交的消息的位置,这个值决定了客户端可以读取到的消息最大范围,超过高水位标记的消息【5、6】属于未提交消息,客户端读取不到。
日志末端位移:表示下一条待写入消息的位移,也就是说LEO指向的位置是没有消息的。当写入一条消息LEO会加1.
以上三个位移无论是在Leader副本还是Follower副本都具有。而分区的HW值就是Leader副本的HW值。并且Leader副本所在的broker上还保存了Follower副本的HW和LEO水位值。
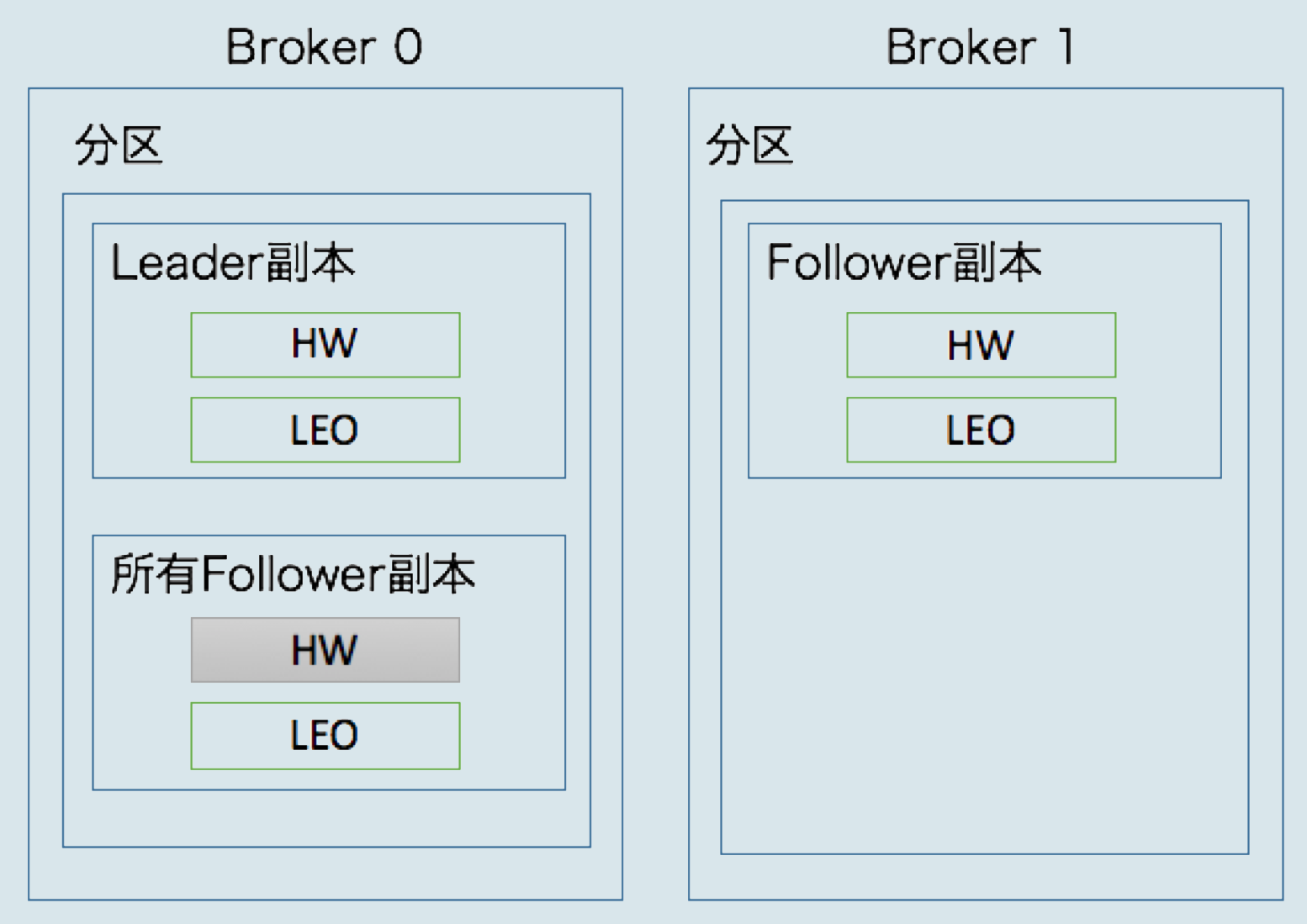
何时更新LEO值
从上图看到Leader副本所在broker上保存了所有Follower副本的HW和LEO值,同时Follower副本所在broker也保存了自己的HW和LEO。
生产者向Leader副本写入数据,那么Leader的LEO值就会增加;Follower向Leader拉取数据并写入自己的日志文件时Follower的LEO也会增加。
在Leader的broker上保存的Follower副本的LEO值是在Leader收到Follower的拉取数据请求之后和真正发送数据给Follower之前进行更新的,而且来拉取的时候Follower会发送自己的HW值,Leader上保存的Follower副本的LEO值就是Follower拉取数据时发送过来的自己的HW值。
何时更新HW值
Follower收到数据然后就要写入日志,之后就要更新自己的LEO值,更新完成后再去更新自己的HW值,原则就是Leader发送过来的数据中包含Leader自己的HW,所以Follower在更新完自己的LEO之后尝试更新自己的HW的时候会比较Leader的HW和自己的LEO哪个最小,它取最小值来设置自己的HW值。
Leader更新自己的HW发生在:
-
生产者写入新的消息,Leader更新了自己的LEO后尝试更新自己的HW
-
Leader从日志中读取了数据并发送给Follower之后尝试更新自己的HW
上面都是尝试更新,而不是一定更新,因为更新原则是取Leader副本的LEO和它所保存的所有Follower副本的LEO的最小值为Leader副本的HW值。比如在初始状态(LEO为0、HW为0,保存的Follower的LEO也为0)下如果写入一条消息虽然Leader更新了自己的LEO为1,而此时保存的的Follower的LEO为0,取最小值就是0,所以HW也是0,故不需要更新。
上述机制由于有时间差问题导致Follower需要进行两轮拉取才能完成HW的更新,所以会出现数据丢失情况,所以在0.11版本中引入了Leader Epoch机制来解决。
如何判定不同步
这里就有一个问题,如何被认定ISR中的副本落后Leader太久呢也就是判断不同步的标准是什么?0.9版本之前是按照消息个数来做的,0.9之后是时间,默认是10秒,如果一个Follower副本落后Leader的时间持续超过10秒则该Follower被认为不是同步的。
主题和分区的日常管理
创建主题
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --create --topic TestCCC --partitions 3 --replication-factor 3
列出所有主题
kafka-topics.sh --list --bootstrap-server 172.16.100.10:9092
查看主题详情
kafka-topics.sh --describe --bootstrap-server 172.16.100.10:9092 --topic TestCCC
删除主题
kafka-topics.sh --delete --bootstrap-server 172.16.100.10:9092 --topic TestCCC
这只是标记主题为删除,因为它是一个异步操作,如果发现某些时候删除了主题但是其ZK中的节点包括磁盘数据还都在,你可以手动清理一下:
删除ZK中/admin/delete_topics下的需要删除的主题名称
手动删除磁盘上的该主题分区目录
在ZK中执行 rmr /controller 来触发Controller的重新选举,这一步要慎重因为它会造成大规模Leader重新选举,不过只执行前两步也行,只是Controller中的缓存没有更新而已。
修改主题的分区数量
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --alter --topic TestCCC --partitions 4
只支持增加分区数量,不支持减少。
说明:这里你可能发现命令中使用的都是 –bootstrap-server而不是之前的–zookeeper参数,因为使用–bootstrap-server是目前操作kafka的标准方式,而且也会经过kafka的安全体系。
这只是标记主题为删除,因为它是一个异步操作,如果发现某些时候删除了主题但是其ZK中的节点包括磁盘数据还都在,你可以手动清理一下:
删除ZK中/admin/delete_topics下的需要删除的主题名称
手动删除磁盘上的该主题分区目录
在ZK中执行 rmr /controller 来触发Controller的重新选举,这一步要慎重因为它会造成大规模Leader重新选举,不过只执行前两步也行,只是Controller中的缓存没有更新而已。
修改主题的分区数量
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --alter --topic TestCCC --partitions 4
只支持增加分区数量,不支持减少。
说明:这里你可能发现命令中使用的都是 –bootstrap-server而不是之前的–zookeeper参数,因为使用–bootstrap-server是目前操作kafka的标准方式,而且也会经过kafka的安全体系。
