RPC学习


设计协议
相对于 HTTP 的用处,RPC 更多的是负责应用间的通信,所以性能要求相对更高。但 HTTP 协议的数据包大小相对请求数据本身要大很多,又需要加入很多无用的内容,比如换行符号、回车符等;
还有一个更重要的原因是,HTTP 协议属于无状态协议,客户端无法对请求和响应进行关联,每次请求都需要重新建立连接,响应完成后再关闭连接。因此,对于要求高性能的 RPC 来说,HTTP 协议基本很难满足需求,所以
RPC 会选择设计更紧凑的私有协议。
协议要点:
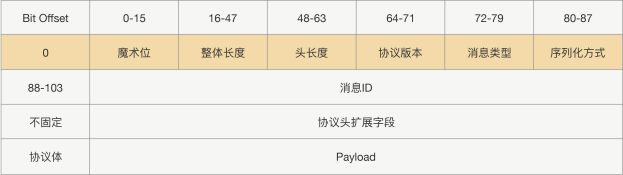
在协议头里面,我们除了会放协议长度、序列化方式,还会放一些像协议标示、消息 ID、消息类型这样的参数,而协议体一般只放请求接口方法、请求的业务参数值和一些扩展属性。这样一个完整的 RPC 协议大概就出来了,协议头是由一堆固定的长度参数组成,而协议体是根据请求接口和参数构造的,长度属于可变的,具体协议如下图所示:

可扩展:
如果加新参数的话,首先不可以放在协议头,那么放在协议体中可以吗
答案是不可以的
因为协议体中的内容都是要经过序列和反序列化的,如果要获取到你参数的值,就必须把整个协议体里面的数据经过反序列化出来,在某些场景下这样做代价有点高
那就变成协议头(固定部分,扩展部分),协议体
序列化和反序列化
实际上任何一种序列化框架,核心思想就是设计一种序列化协议,将对象的类型、属性类型、属性值一一按照固定的格式写到二进制字节流中来完成序列化,再按照固定的格式一一读出对象的类型、属性类型、属性值,通过这些信息重新创建出一个新的对象,来完成反序列化
常见的序列化方式有:JDK,Json,Hessian,Protobuf序列化方式。
选择序列化方式要考虑的因素
-
性能和效率
-
空间开销‘
-
通用性和兼容性
-
安全性

首选的还是 Hessian 与 Protobuf,因为他们在性能、时间开销、空间开销、通用性、兼容性和安全性上,都满足了我们的要求。其中 Hessian 在使用上更加方便,在对象的兼容性上更好;Protobuf 则更加高效,通用性上更有优势。
在使用过程中编码需注意那些问题
1.对象要尽量简单,没有太多的依赖关系,属性不要太多,尽量高内聚;
2. 入参对象与返回值对象体积不要太大,更不要传太大的集合;
3. 尽量使用简单的、常用的、开发语言原生的对象,尤其是集合类;
4. 对象不要有复杂的继承关系,最好不要有父子类的情况
IO
零拷贝
取消用户空间和内核空间的拷贝
应用进程的每一次读写可以直接将数据从内核区中取出或者写入,再通过DMA将内核中的数据拷贝到网卡或从网卡拷贝到内核。
所以解决方式就是使用户空间和内核空间的数据都在一个地方存取,那就是虚拟内存。
RPC协议在传输数据过程中,中间可能会拆分成好几个数据包,也可能会合并其他请求的数据包,所以消息都需要有边界。那么一端的机器收到消息之后,就需要对数据包进行处理,根据边界对数据包进行分割和合并,最终获得一条完整的消息。
收到消息后,对数据包的分割和合并,是在用户空间完成,还是在内核空间完成的
Netty 的零拷贝就是为了解决这个问题,在用户空间对数据操作进行优化。
Netty 框架中很多内部的 ChannelHandler 实现类,都是通过 CompositeByteBuf、slice、wrap 操作来处理 TCP 传输中的拆包与粘包问题的。
那么 Netty 解决用户空间与内核空间之间的数据拷贝问题的方法:
Netty 的 ByteBuffer 可以采用 Direct Buffers,使用堆外直接内存进行 Socketd 的读写操作,最终的效果与虚拟内存所实现的效果是一样的。
SPI
设计RPC框架时,为了实现插件化架构,可将功能点抽象成接口,将接口与实现分离,并提供接口的默认实现
利用SPI(服务发现机制),可动态的为接口寻找服务
实现:在Classpath 下的 METAINF/services 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体实现类。
服务发现
还是最终一致性性能更好
