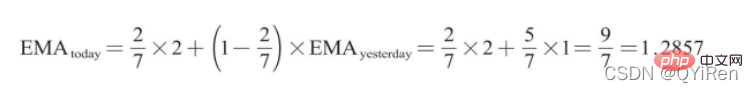Python随机森林模型实例详解

本篇文章给大家带来了关于Python的相关知识,其中主要整理了随机森林模型的相关问题,包括了集成模型简介、随机森林模型基本原理、使用sklearn实现随机森林模型等等内容,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
1 集成模型简介
集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。
集成学习模型的常见算法有Bagging算法和Boosting算法两种。
Bagging算法的典型机器学习模型为随机森林模型,而Boosting算法的典型机器学习模型则为AdaBoost、GBDT、XGBoost和LightGBM模型。
1.1 Bagging算法简介
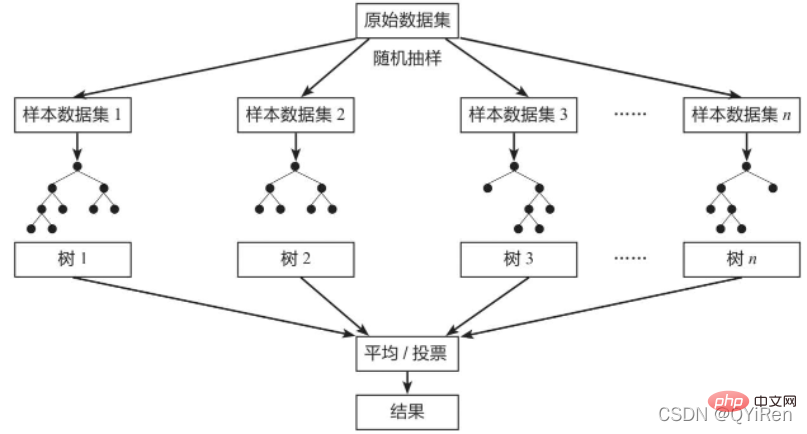
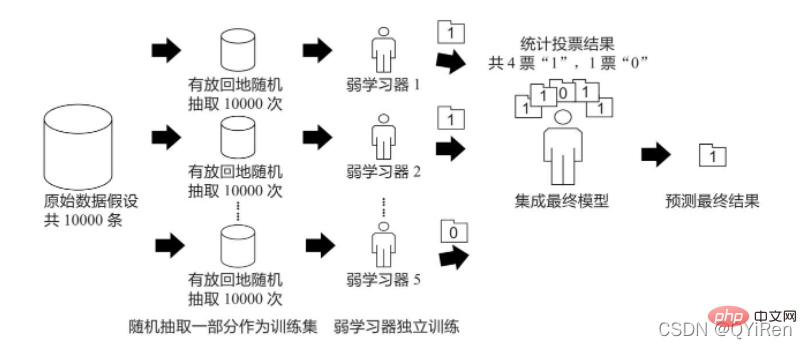
Bagging算法的原理类似投票,每个弱学习器都有一票,最终根据所有弱学习器的投票,按照“少数服从多数”的原则产生最终的预测结果,如下图所示。
假设原始数据共有10000条,从中随机有放回地抽取10000次数据构成一个新的训练集(因为是随机有放回抽样,所以可能出现某一条数据多次被抽中,也有可能某一条数据一次也没有被抽中),每次使用一个训练集训练一个弱学习器。这样有放回地随机抽取n次后,训练结束时就能获得由不同的训练集训练出的n个弱学习器,根据这n个弱学习器的预测结果,按照“少数服从多数”的原则,获得一个更加准确、合理的最终预测结果。
具体来说,在分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果。
假设原始数据共有10000条,从中随机有放回地抽取10000次数据构成一个新的训练集(因为是随机有放回抽样,所以可能出现某一条数据多次被抽中,也有可能某一条数据一次也没有被抽中),每次使用一个训练集训练一个弱学习器。这样有放回地随机抽取n次后,训练结束时就能获得由不同的训练集训练出的n个弱学习器,根据这n个弱学习器的预测结果,按照“少数服从多数”的原则,获得一个更加准确、合理的最终预测结果。
具体来说,在分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果。
1.2 Boosting算法简介
Boosting算法的本质是将弱学习器提升为强学习器,它和Bagging算法的区别在于:Bagging算法对待所有的弱学习器一视同仁;而Boosting算法则会对弱学习器“区别对待”,通俗来讲就是注重“培养精英”和“重视错误”。
“培养精英”就是每一轮训练后对预测结果较准确的弱学习器给予较大的权重,对表现不好的弱学习器则降低其权重。这样在最终预测时,“优秀模型”的权重是大的,相当于它可以投出多票,而“一般模型”只能投出一票或不能投票。
“重视错误”就是在每一轮训练后改变训练集的权值或概率分布,通过提高在前一轮被弱学习器预测错误的样例的权值,降低前一轮被弱学习器预测正确的样例的权值,来提高弱学习器对预测错误的数据的重视程度,从而提升模型的整体预测效果。
2 随机森林模型基本原理
随机森林(Random Forest)是一种经典的Bagging模型,其弱学习器为决策树模型。如下图所示,随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型)或者投票情况(针对分类模型)来获取最终结果。
为了保证模型的泛化能力(或者说通用能力),随机森林模型在建立每棵树时,往往会遵循“数据随机”和“特征随机”这两个基本原则。
数据随机:从所有数据当中有放回地随机抽取数据作为其中一个决策树模型的训练数据。例如,有1000个原始数据,有放回地抽取1000次,构成一组新的数据,用于训练某一个决策树模型。
特征随机:如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征。
与单独的决策树模型相比,随机森林模型由于集成了多个决策树,其预测结果会更准确,且不容易造成过拟合现象,泛化能力更强。
3 使用sklearn实现随机森林模型
随机森林模型既能进行分类分析,又能进行回归分析,对应的模型分别为:
·随机森林分类模型(RandomForestClassifier)
·随机森林回归模型(RandomForestRegressor)
随机森林分类模型的弱学习器是分类决策树模型,随机森林回归模型的弱学习器则是回归决策树模型。
代码如下。
为了保证模型的泛化能力(或者说通用能力),随机森林模型在建立每棵树时,往往会遵循“数据随机”和“特征随机”这两个基本原则。
数据随机:从所有数据当中有放回地随机抽取数据作为其中一个决策树模型的训练数据。例如,有1000个原始数据,有放回地抽取1000次,构成一组新的数据,用于训练某一个决策树模型。
特征随机:如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征。
与单独的决策树模型相比,随机森林模型由于集成了多个决策树,其预测结果会更准确,且不容易造成过拟合现象,泛化能力更强。
3 使用sklearn实现随机森林模型
随机森林模型既能进行分类分析,又能进行回归分析,对应的模型分别为:
·随机森林分类模型(RandomForestClassifier)
·随机森林回归模型(RandomForestRegressor)
随机森林分类模型的弱学习器是分类决策树模型,随机森林回归模型的弱学习器则是回归决策树模型。
代码如下。
from sklearn.ensemble import RandomForestClassifier X = [[1,2],[3,4],[5,6],[7,8],[9,10]] y = [0,0,0,1,1] # 设置弱学习器数量为10 model = RandomForestClassifier(n_estimators=10,random_state=123) model.fit(X,y) model.predict([[5,5]]) # 输出为:array([0])4 案例:股票涨跌预测模型
4.1 股票衍生变量生成
本节讲解如何利用股票的基本数据获取一些衍生变量数据,如股票技术分析常用的均线指标5日均线价格MA5与10日均线价格MA10、相对强弱指标RSI、动量指标MOM、指数移动平均值EMA、异同移动平均线MACD等。
4.1.1 获取股票基本数据
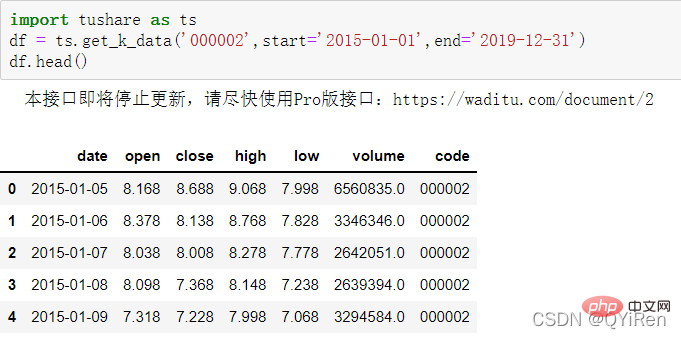
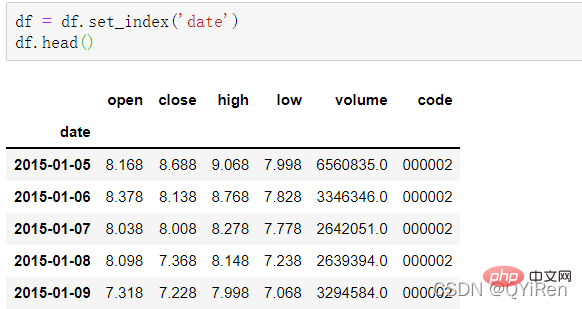
首先用get_k_data()函数获取2015-01-01到2019-12-31的股票基本数据,代码如下。
前5行数据如下图所示,其中缺失的数据为节假日(非交易日)数据。
用set_index()函数将date列设置为行索引,代码如下。
用set_index()函数将date列设置为行索引,代码如下。
4.1.2 生成简单衍生变量
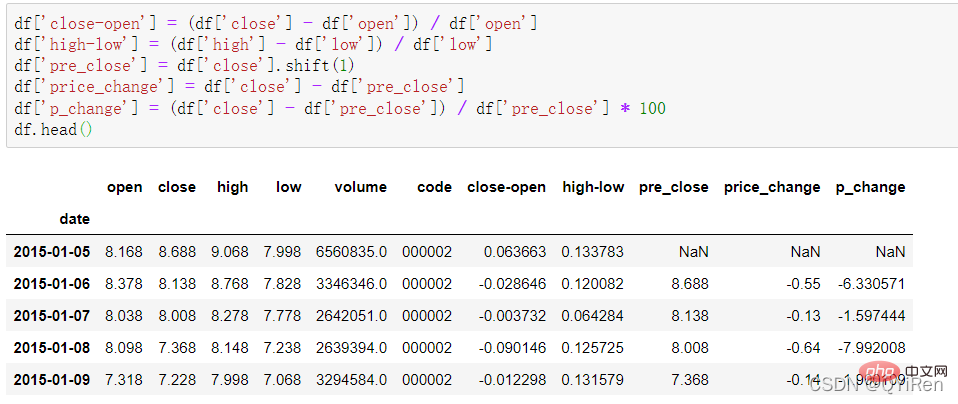
通过如下代码可以生成一些简单的衍生变量数据。
close-open表示(收盘价-开盘价)/开盘价;
high-low表示(最高价-最低价)/最低价;
pre_close表示昨日收盘价,用shift(1)将close列的所有数据向下移动1行并形成新的1列,如果是shift(-1)则表示向上移动1行;
price_change表示今日收盘价-昨日收盘价,即当天的股价变化;
p_change表示当天股价变化的百分比,也称为当天股价的涨跌幅。
close-open表示(收盘价-开盘价)/开盘价;
high-low表示(最高价-最低价)/最低价;
pre_close表示昨日收盘价,用shift(1)将close列的所有数据向下移动1行并形成新的1列,如果是shift(-1)则表示向上移动1行;
price_change表示今日收盘价-昨日收盘价,即当天的股价变化;
p_change表示当天股价变化的百分比,也称为当天股价的涨跌幅。
4.1.3 生成移动平均线指标MA值
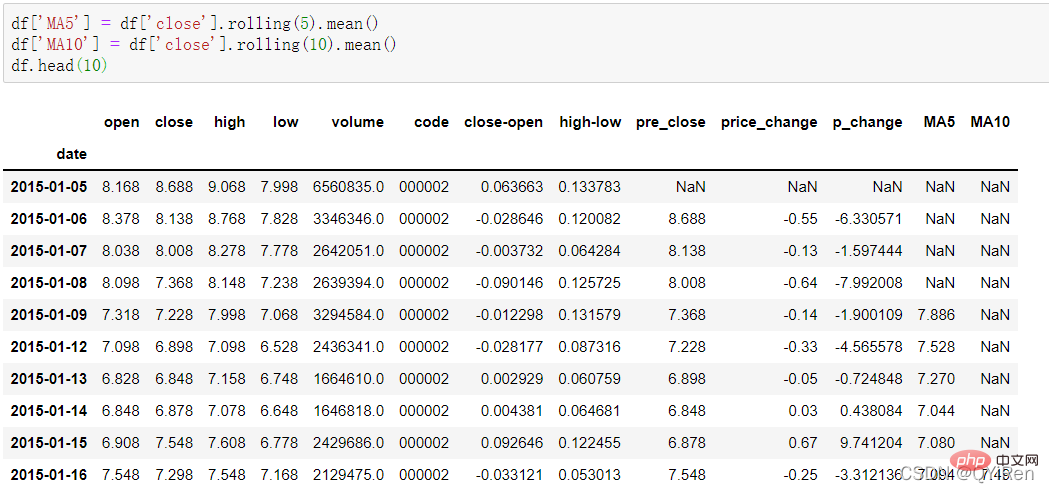
通过如下代码可以生成股价的5日移动平均值和10日移动平均值。
注意:rolling函数的使用
其中,MA是移动平均线的意思,“平均”是指最近n天收盘的算术平均值,“移动”是指在计算中始终采用最近n天的价格数据。
例如:MA5的计算
其中,MA是移动平均线的意思,“平均”是指最近n天收盘的算术平均值,“移动”是指在计算中始终采用最近n天的价格数据。
例如:MA5的计算
根据上述数据,5号的MA5值为(1.2+1.4+1.6+1.8+2.0)/5=1.6,而6号的MA5值则为(1.4+1.6+1.8+2.0+2.2)/5=1.8,依此类推。将一段时期内股价的移动平均值连成曲线,即为移动平均线。同理,MA10为从计算当天起前10天的股价平均值。
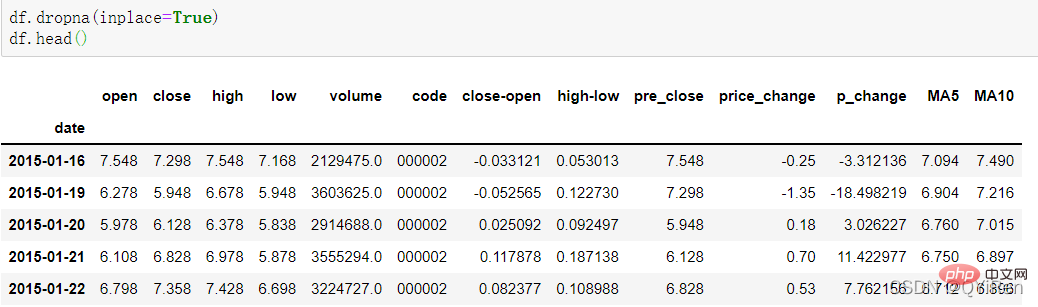
在计算像MA5这样的数据时,因为最开始的4天数据量不够,这4天对应的移动平均值是无法计算出来的,所以会产生空值NaN。通常会用dropna()函数删除空值,以免在后续计算中出现因空值造成的问题,代码如下。
根据上述数据,5号的MA5值为(1.2+1.4+1.6+1.8+2.0)/5=1.6,而6号的MA5值则为(1.4+1.6+1.8+2.0+2.2)/5=1.8,依此类推。将一段时期内股价的移动平均值连成曲线,即为移动平均线。同理,MA10为从计算当天起前10天的股价平均值。
在计算像MA5这样的数据时,因为最开始的4天数据量不够,这4天对应的移动平均值是无法计算出来的,所以会产生空值NaN。通常会用dropna()函数删除空值,以免在后续计算中出现因空值造成的问题,代码如下。
可以看到16号以前的行被删除。
可以看到16号以前的行被删除。
4.1.4 用TA-Lib库生成相对强弱指标RSI值
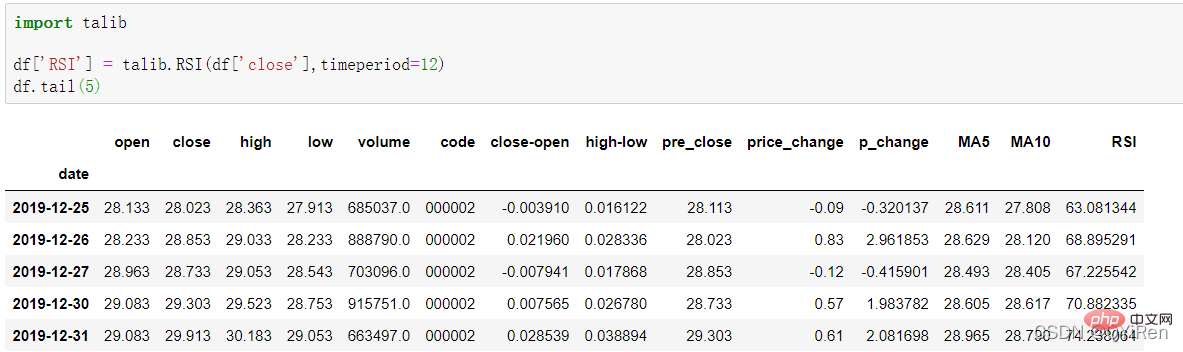
通过如下代码可以生成相对强弱指标RSI值。
RSI值能反映短期内股价涨势相对于跌势的强弱,帮助我们更好地判断股价的涨跌趋势。
RSI值越大,涨势相对于跌势越强,反之则涨势相对于跌势越弱。
RSI值的计算公式如下。
RSI值能反映短期内股价涨势相对于跌势的强弱,帮助我们更好地判断股价的涨跌趋势。
RSI值越大,涨势相对于跌势越强,反之则涨势相对于跌势越弱。
RSI值的计算公式如下。
举例:
举例:
根据上表数据,取N=6,可求得6日平均上涨价格为(2+2+2)/6=1,6日平均下跌价格为(1+1+1)/6=0.5,所以RSI值为(1/(1+0.5))×100=66.7。
通常情况下,RSI值位于20~80之间,超过80则为超买状态,低于20则为超卖状态,等于50则认为买卖双方力量均等。例如,如果连续6天股价都是上涨,则6日平均下跌价格为0,6日RSI值为100,表明此时股票买方处于非常强势的地位,但也提醒投资者要警惕此时可能也是超买状态,需要预防股价下跌的风险。
根据上表数据,取N=6,可求得6日平均上涨价格为(2+2+2)/6=1,6日平均下跌价格为(1+1+1)/6=0.5,所以RSI值为(1/(1+0.5))×100=66.7。
通常情况下,RSI值位于20~80之间,超过80则为超买状态,低于20则为超卖状态,等于50则认为买卖双方力量均等。例如,如果连续6天股价都是上涨,则6日平均下跌价格为0,6日RSI值为100,表明此时股票买方处于非常强势的地位,但也提醒投资者要警惕此时可能也是超买状态,需要预防股价下跌的风险。
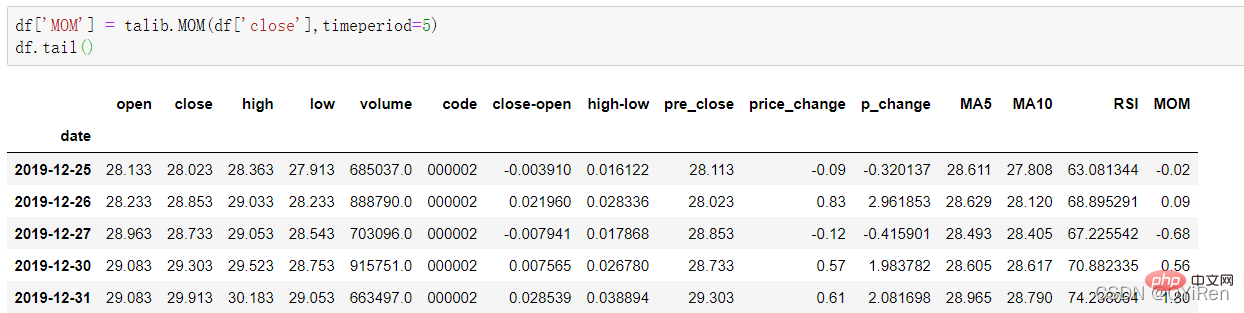
4.1.5 用TA-Lib库生成动量指标MOM值
通过如下代码可以生成动量指标MOM值。
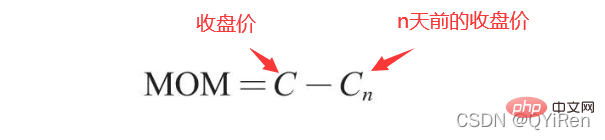
MOM是momentum(动量)的缩写,它反映了一段时期内股价的涨跌速度,计算公式如下。
MOM是momentum(动量)的缩写,它反映了一段时期内股价的涨跌速度,计算公式如下。
举例:
举例:
假设要计算6号的MOM值,而前面的代码中设置参数timeperiod为5,那么就需要用6号的收盘价减去1号的收盘价,即6号的MOM值为2.2-1.2=1,同理,7号的MOM值为2.4-1.4=1。将连续几天的MOM值连起来就构成一条反映股价涨跌变动的曲线。

假设要计算6号的MOM值,而前面的代码中设置参数timeperiod为5,那么就需要用6号的收盘价减去1号的收盘价,即6号的MOM值为2.2-1.2=1,同理,7号的MOM值为2.4-1.4=1。将连续几天的MOM值连起来就构成一条反映股价涨跌变动的曲线。
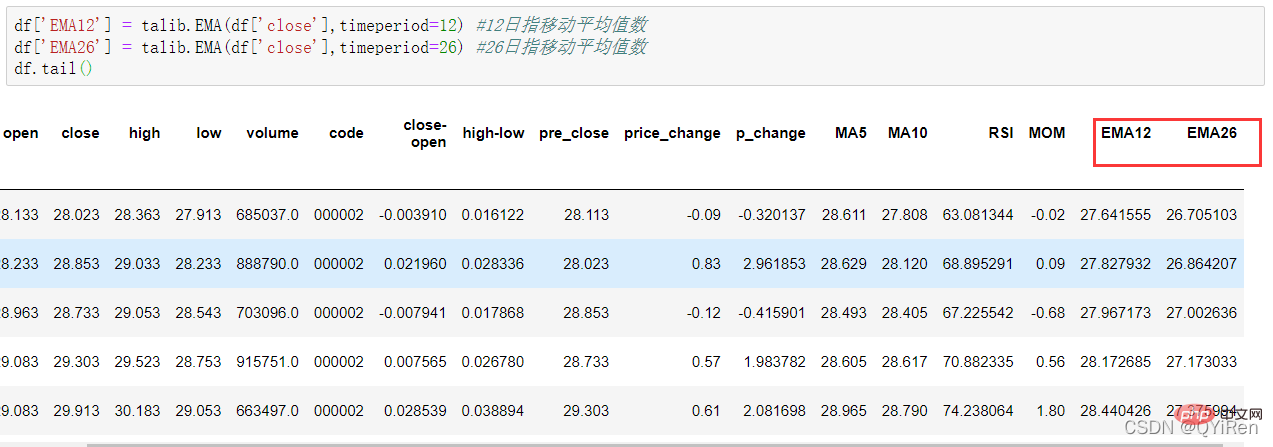
4.1.6 用TA-Lib库生成指数移动平均值EMA
通过如下代码可以生成指数移动平均值EMA。
EMA是以指数式递减加权的移动平均,并根据计算结果进行分析,用于判断股价未来走势的变动趋势。
EMA的计算公式如下。
EMA是以指数式递减加权的移动平均,并根据计算结果进行分析,用于判断股价未来走势的变动趋势。
EMA的计算公式如下。
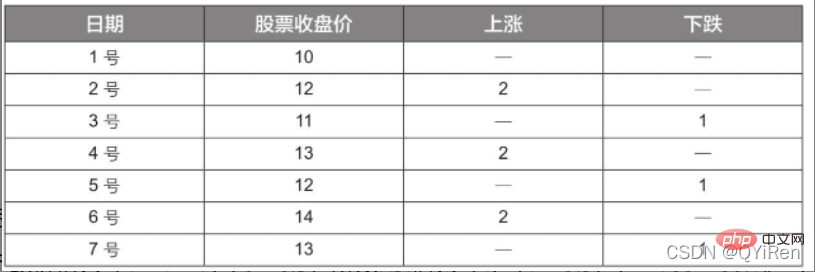
其中,EMAtoday为当天的EMA值;Pricetoday为当天的收盘价;EMAyesterday为昨天的EMA值;α为平滑指数,一般取值为2/(N+1),N表示天数,当N为6时,α为2/7,对应的EMA称为EMA6,即6日指数移动平均值。公式不断递归,直至第1个EMA值出现(第1个EMA值通常为开头5个数的均值)。
举例:EMA6
取第1个EMA值为开头5个数的均值,故前5天都没有EMA值;6号的EMA值就是第1个EMA值,为前5天的均值,即1;7号的EMA值为第2个EMA值,计算过程如下。
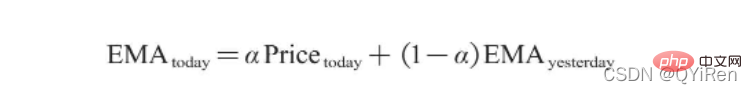
其中,EMAtoday为当天的EMA值;Pricetoday为当天的收盘价;EMAyesterday为昨天的EMA值;α为平滑指数,一般取值为2/(N+1),N表示天数,当N为6时,α为2/7,对应的EMA称为EMA6,即6日指数移动平均值。公式不断递归,直至第1个EMA值出现(第1个EMA值通常为开头5个数的均值)。
举例:EMA6
取第1个EMA值为开头5个数的均值,故前5天都没有EMA值;6号的EMA值就是第1个EMA值,为前5天的均值,即1;7号的EMA值为第2个EMA值,计算过程如下。
4.1.7 用TA-Lib库生成异同移动平均线MACD值
通过如下代码可以生成异同移动平均线MACD值。
MACD是股票市场上的常用指标,它是基于EMA值的衍生变量,计算方法比较复杂,感兴趣的读者可以自行了解。这里只需要知道MACD是一种趋势类指标,其变化代表着市场趋势的变化,不同K线级别的MACD代表当前级别周期中的买卖趋势。
MACD是股票市场上的常用指标,它是基于EMA值的衍生变量,计算方法比较复杂,感兴趣的读者可以自行了解。这里只需要知道MACD是一种趋势类指标,其变化代表着市场趋势的变化,不同K线级别的MACD代表当前级别周期中的买卖趋势。
4.2 模型搭建
4.2.1 引入需要搭建的库
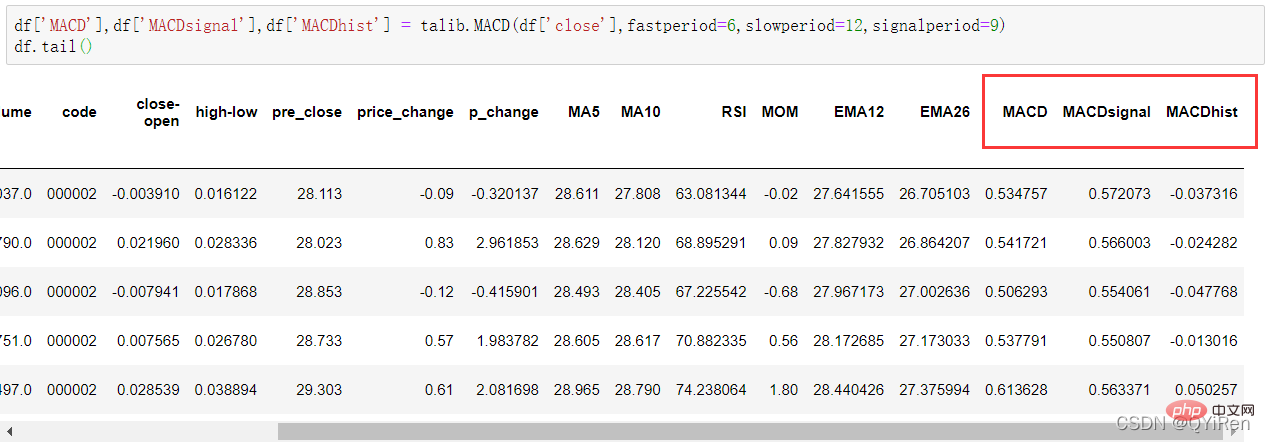
# 导入相关库 import tushare as ts import numpy as np import pandas as pd import talib import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score4.2.2 获取数据
# 1.股票基本数据获取 import tushare as ts df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31') df = df.set_index('date') # 2.简单衍生变量数据构造 df['close-open'] = (df['close'] - df['open']) / df['open'] df['high-low'] = (df['high'] - df['low']) / df['low'] df['pre_close'] = df['close'].shift(1) df['price_change'] = df['close'] - df['pre_close'] df['p_change'] = (df['close'] - df['pre_close']) / df['pre_close'] * 100 # 3.移动平均线相关数据构造 df['MA5'] = df['close'].rolling(5).mean() df['MA10'] = df['close'].rolling(10).mean() df.dropna(inplace=True) # 4.通过TA-Lib库构造衍生变量数据 df['RSI'] = talib.RSI(df['close'],timeperiod=12) df['MOM'] = talib.MOM(df['close'],timeperiod=5) df['EMA12'] = talib.EMA(df['close'],timeperiod=12) #12日指移动平均值数 df['EMA26'] = talib.EMA(df['close'],timeperiod=26) #26日指移动平均值数 df['MACD'],df['MACDsignal'],df['MACDhist'] = talib.MACD(df['close'],fastperiod=6,slowperiod=12,signalperiod=9) df.dropna(inplace=True)4.2.3 提取特征变量和目标变量
X = df[['close','volume','close-open','MA5','MA10','high-low','RSI','MOM','EMA12','MACD','MACDsignal','MACDhist']] y = np.where(df['price_change'].shift(-1) > 0,1,-1)首先强调最核心的一点:应该是用当天的股价数据预测下一天的股价涨跌情况,所以目标变量y应该是下一天的股价涨跌情况。为什么是用当天的股价数据预测下一天的股价涨跌情况呢?这是因为特征变量中的很多数据只有在当天交易结束后才能确定(例如,收盘价close只有收盘了才有),所以当天正在交易时的股价涨跌情况是无法预测的,而等到收盘时尽管所需数据齐备,但是当天的股价涨跌情况已成定局,也就没有必要预测了,所以是用当天的股价数据预测下一天的股价涨跌情况。
第2行代码中使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值。其中df['price_change'].shift(-1)是利用shift()函数将price_change(股价变化)这一列的所有数据向上移动1行,这样就获得了每一行对应的下一天的股价变化。因此,这里的判断条件就是下一天的股价变化是否大于0,如果大于0,说明下一天股价涨了,则y赋值为1;如果不大于0,说明下一天股价不变或跌了,则y赋值为-1。预测结果就只有1或-1两种分类。
4.2.4 划分训练集和测试集
这里需要注意的是,划分要按照时间序列进行,而不能用train_test_split()函数进行随机划分。这是因为股价的变化趋势具有时间性特征,而随机划分会破坏这种特征,所以需要根据当天的股价数据预测下一天的股价涨跌情况,而不能根据任意一天的股价数据预测下一天的股价涨跌情况。
将前90%的数据作为训练集,后10%的数据作为测试集,代码如下。
X_length = X.shape[0] split = int(X_length * 0.9) X_train,X_test = X[:split],X[split:] y_train,y_test = y[:split],y[split:]4.2.5 模型搭建
model = RandomForestClassifier(max_depth=3,n_estimators=10,min_samples_leaf=10,random_state=123) model.fit(X_train,y_train)设置模型参数:决策树的最大深度max_depth设置为3,即每个决策树最多只有3层;弱学习器(即决策树模型)的个数n_estimators设置为10,即该随机森林中共有10个决策树;叶子节点的最小样本数min_samples_leaf设置为10,即如果叶子节点的样本数小于10则停止分裂;随机状态参数random_state的作用是使每次运行结果保持一致,这里设置的数字123没有特殊含义,可以换成其他数字。
4.3 模型评估与使用
4.3.1 预测下一天的股价涨跌情况
用predict_proba()函数可以预测属于各个分类的概率,代码如下。
用predict_proba()函数可以预测属于各个分类的概率,代码如下。

4.3.2 模型准确度评估
通过如下代码可以查看整体的预测准确度。
打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。

打印输出score为0.40,说明模型对整个测试集中约40%的数据预测正确。这一预测准确度并不算高,也的确符合股票市场千变万化的特点。
4.3.3 分析特征变量的特征重要性
通过如下代码可以分析各个特征变量的特征重要性。
由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。

由图可知,当日收盘价close、MA5、MACDhist相关指标等特征变量对下一天股价涨跌结果的预测准确度影响较大。
4.4 参数调优
from sklearn.model_selection import GridSearchCV parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]} new_model = RandomForestClassifier(random_state=123) grid_search = GridSearchCV(new_model,parameters,cv=6,scoring='accuracy') grid_search.fit(X_train,y_train) grid_search.best_params_ # 输出 # {'max_depth': 5, 'min_samples_leaf': 20, 'n_estimators': 5}4.5 收益回测曲线绘制
前面已经评估了模型的预测准确度,不过在商业实战中,更关心它的收益回测曲线(又称为净值曲线),也就是看根据搭建的模型获得的结果是否比不利用模型获得的结果更好。
# 在测试数据上添加一列,预测收益 X_test['prediction'] = model.predict(X_test) # 计算每天的股价变化率 X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1) # 计算累积收益率 # 例如,初始股价是1,2天内的价格变化率为10% # 那么用cumprod()函数可以求得2天后的股价为1×(1+10%)×(1+10%)=1.21 # 此结果也表明2天的收益率为21%。 X_test['origin'] = (X_test['p_change'] + 1).cumprod() # 计算利用模型预测后的收益率 X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod() X_test[['strategy','origin']].dropna().plot() # 设置自动倾斜 plt.gcf().autofmt_xdate() plt.show()可视化结果如下图所示。图中上方的曲线为根据模型得到的收益率曲线,下方的曲线为股票本身的收益率曲线,可以看到,利用模型得到的收益还是不错的。
要说明的是,这里讲解的量化金融内容比较浅显,搭建的模型过于理想化,真正的股市是错综复杂的,股票交易也有很多限制,如不能做空、不能T+0交易,还要考虑手续费等因素。
随机森林模型是一种非常重要的集成模型,它集成了决策树模型的众多优点,又规避了决策树模型容易过度拟合等缺点,在实战中应用较为广泛。
【相关推荐:Python3视频教程 】