一篇文章讲清楚MySQL的聚簇/联合/覆盖索引、回表、索引下推

迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子。
手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:“加班使我快乐”。

面试官: 看你简历上用过MySQL,问你几个简单的问题吧。什么是聚簇索引和非聚簇索引?
这个问题难不住我啊。来之前我看一下一灯MySQL八股文。
我: 举个例子:有这么一张用户表
CREATE TABLE `user` (
`id` int COMMENT "主键ID",
`name` varchar(10) COMMENT "姓名",
`age` int COMMENT "年龄",
PRIMARY KEY (`id`)
) ENGINE=InnoDB CHARSET=utf8 COMMENT="用户表";
用户表中存储了这些数据:
| id | nane | age |
|---|---|---|
| 1 | 一灯 | 18 |
| 2 | 张三 | 22 |
| 3 | 李四 | 21 |
| 4 | 王二 | 19 |
| 5 | 麻子 | 20 |
那么在索引中,这些数据是怎么存储的呢?
MySQL的InnoDB引擎中索引使用的B+树结构。
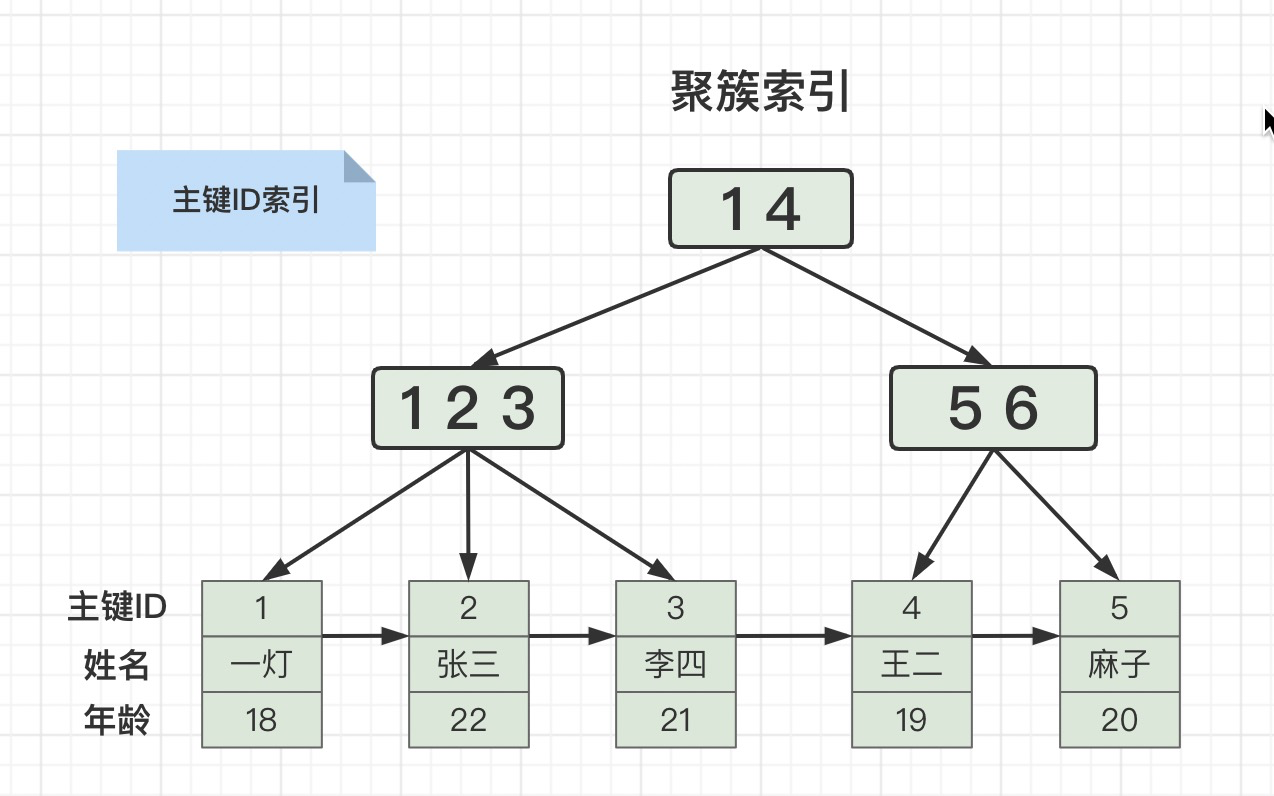
别问为什么根节点存储了(1,4)两个元素,左子节点又存储了(1,2,3)三个元素,下面带有三个叶子节点,叶子节点之间又用有序链表相连?
问就是B+树的特性,不了解的可以翻一下上期的文章。
如上图所示,叶子节点中存储了全部元素的索引,就是聚簇索引。
一般主键索引就是聚簇索引,如果表中没有主键,MySQL也会默认建立一个隐藏主键做主键索引。
什么是非聚簇索引?
假设我们在age(年龄)字段上建一个普通索引,age字段上面的索引存储结构就是下面这样:
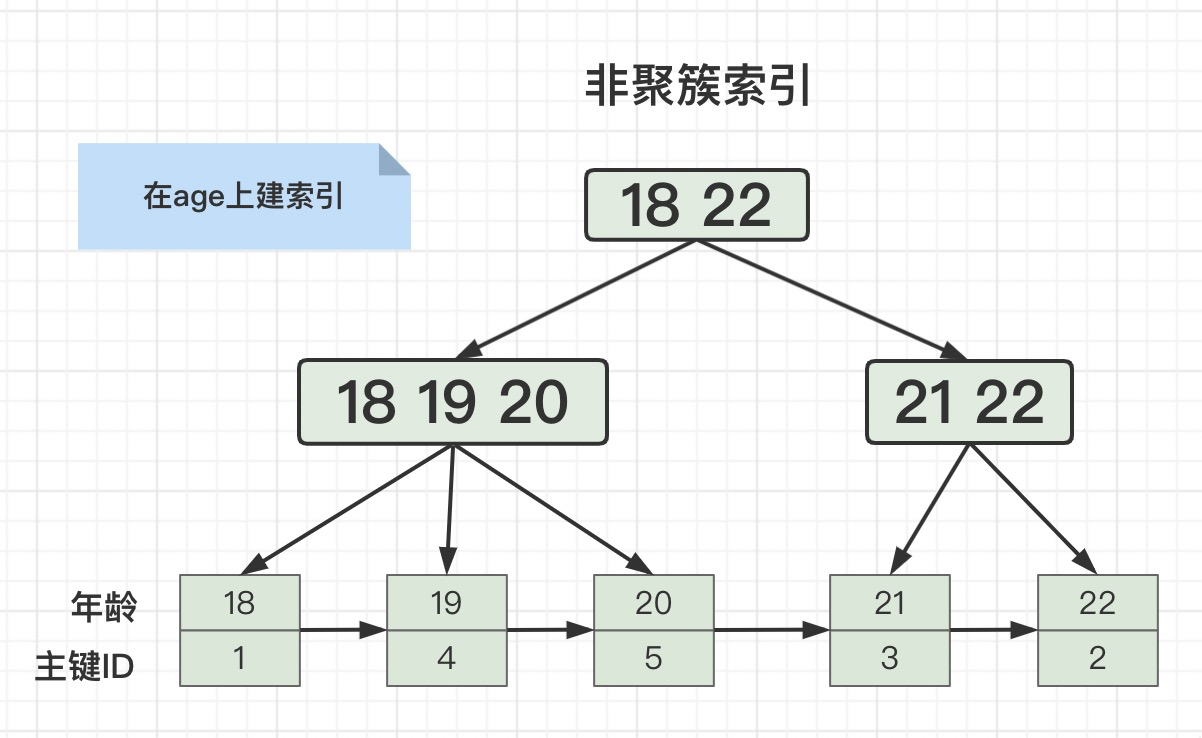
叶子节点中只存储了当前索引字段和主键ID,这样的存储结构就是非聚簇索引。
面试官: 那什么是联合索引呢?
我: 有多个字段组成的索引就是联合索引。
面试官: 【晕】建联合索引有什么好处?它跟在单个字段上建索引有什么区别?
我: 假设有这么一条查询语句。
select * from user where age = 18 and name = "张三";
如果我们在age和name字段上分别建两个索引,这个查询语句只会用到其中一个索引。
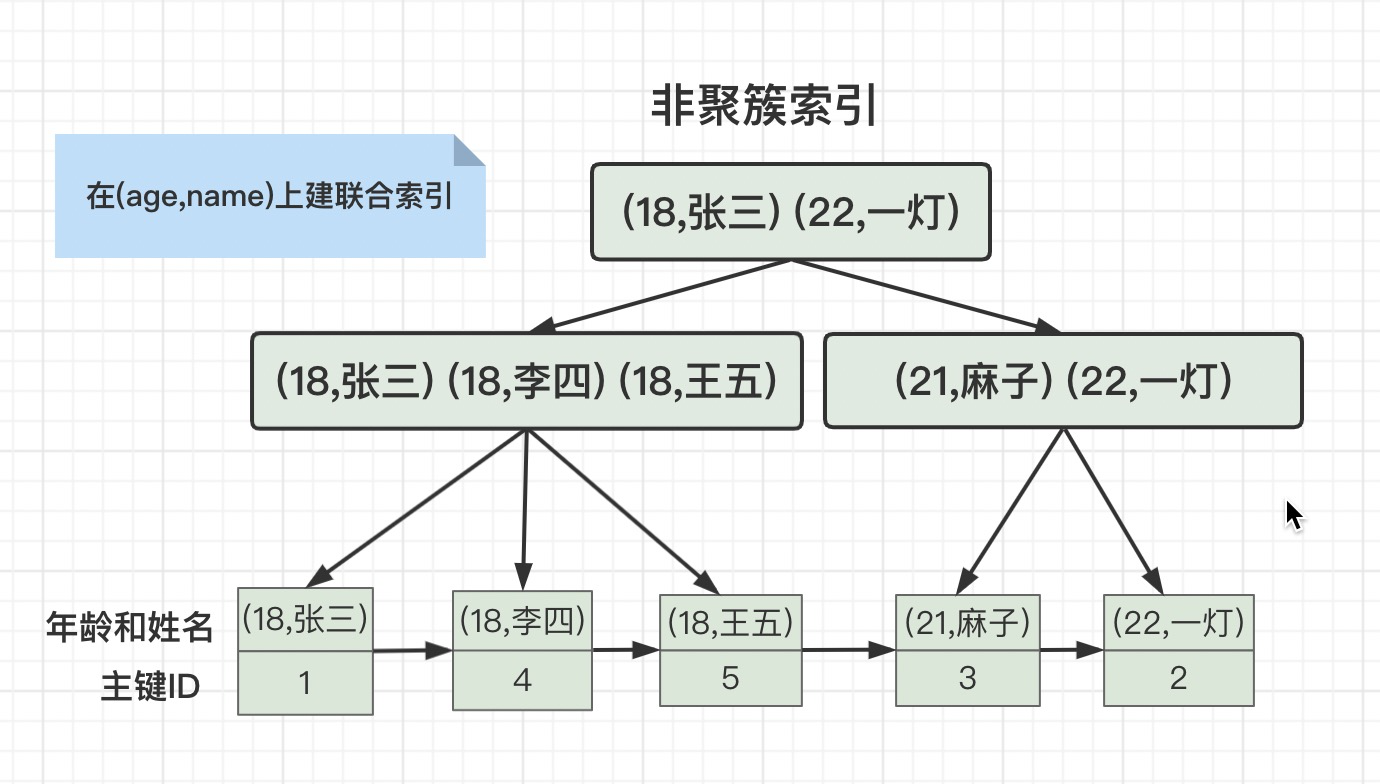
但是我们在age和name字段建一个联合索引(age,name),它的存储结构就变成这样了。
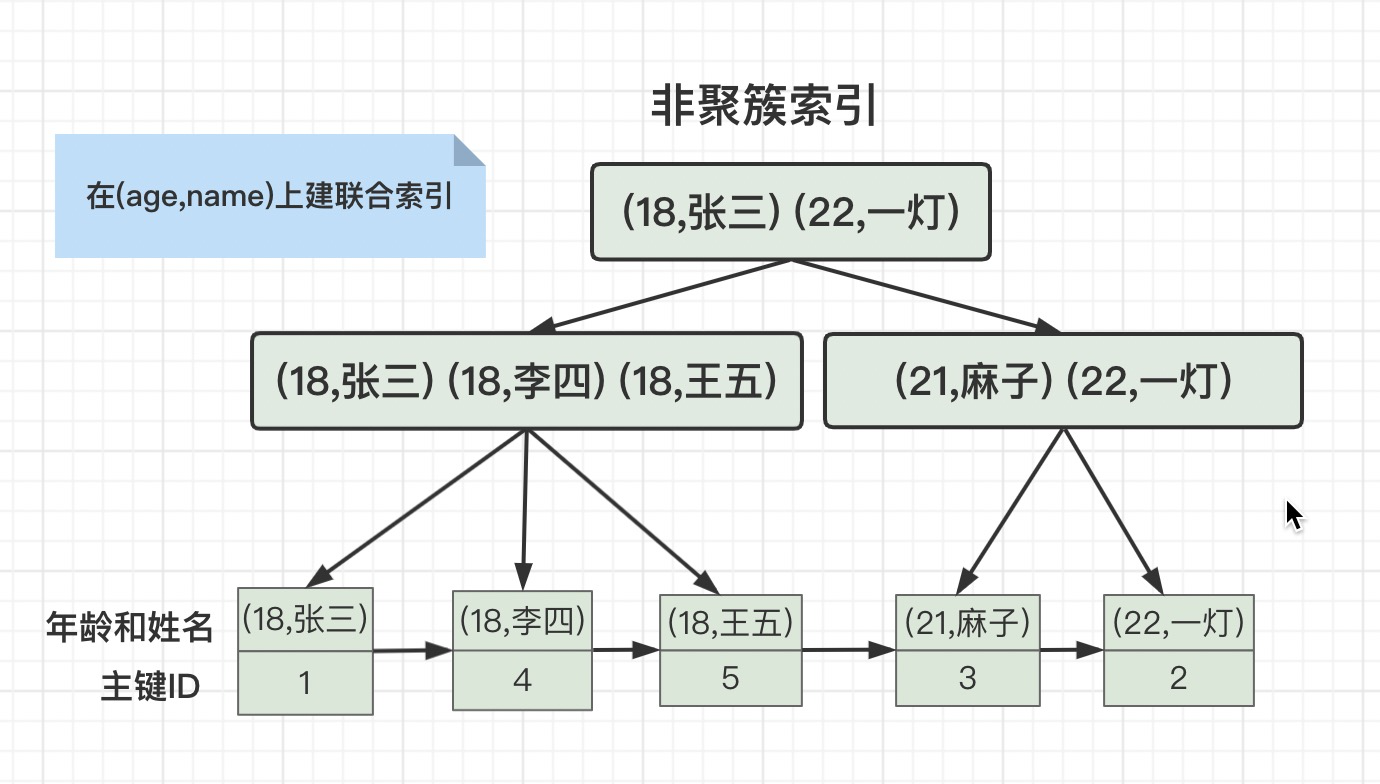
如果只在age上面建索引,会先查询age上面非聚簇索引,有三条age=18的记录,主键ID分别是1、4、5,然后再用这三个ID去查询主键ID的聚簇索引。
如果在age和name上面建联合索引,会先查询age和name上面的非聚簇索引,匹配到一条记录,主键ID是1,然后再用这个ID去查询主键ID的聚簇索引。
由此可以得出,联合索引的优点:大大减少扫描行数。
面试官: 你再说一下什么是最左匹配原则?
我: 最左匹配原则是指在建立联合索引的时候,遵循最左优先,以最左边的为起点任何连续的索引都能匹配上。
当我们在(age,name)上建立联合索引的时候,where条件中只有age可以用到索引,同时有age和name也可以用到索引。但是只有name的时候是无法用到索引的。
为什么会出现这种情况呢?
看上面的图,就理解了,(age,name)的联合索引,是先按照age排序,age相等的行再按照name排序。如果where条件只有一个name,当然无法用到索引。
面试官: 什么是覆盖索引和回表查询?
我: 这个就更简单了,上面已经提到这个知识点了。
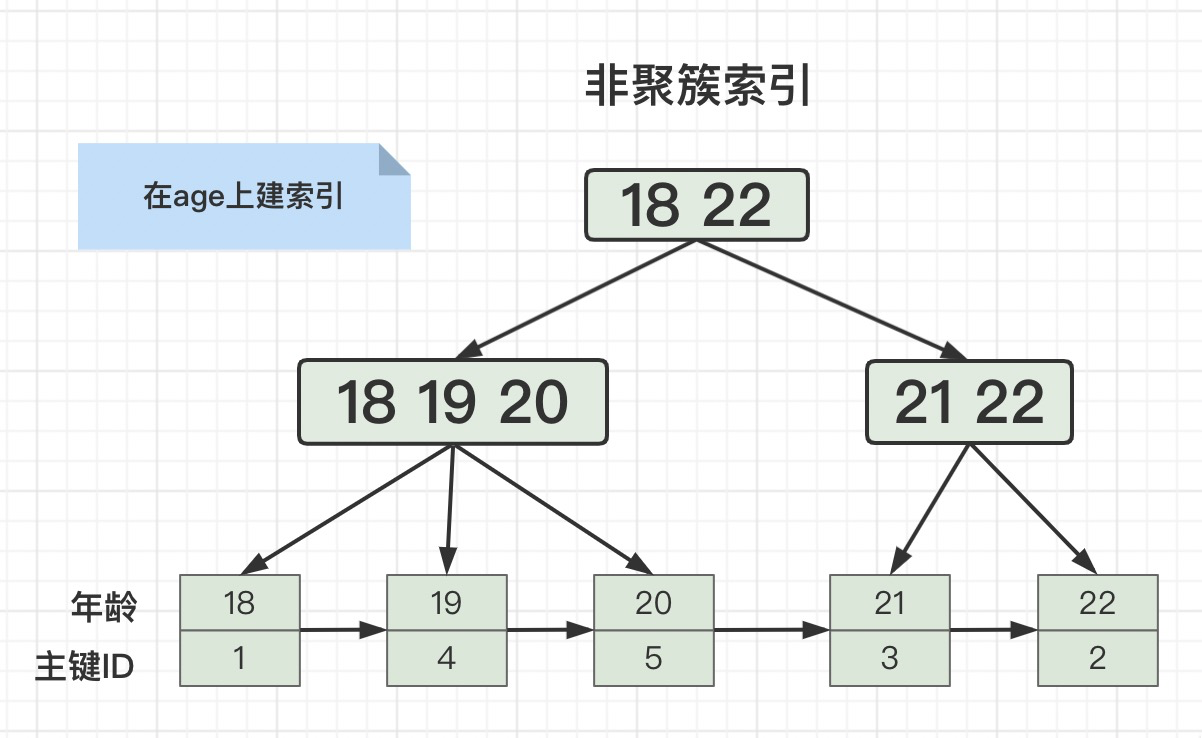
当我们在age上建索引的时候,查询SQL是这样的时候:
select id from user where age = 18;
就会用到覆盖索引,因为ID字段我们使用age索引的时候已经查出来,不需要再二次回表查询了。
但是当查询SQL是这样的时候:
select * from user where age = 18;
想要查询所有字段,就需要二次回表查询。因为我们第一次用age索引的时候只查出来了主键ID,还需要再用主键ID回表查询出所有字段。
面试官: 再问一个,你知道什么是索引下推吗?
这么冷门的问题,你都问的出来,真的要面试造火箭啊!
我: 索引下推(Index Condition Pushdown)是MySQL5.6引入的一个优化索引的特性。
举例:
在(age,name)上面建联合索引,并且查询SQL是这样的时候:
select * from user where age = 18 and name = "张三";
如果没有索引下推,会先匹配出 age = 18 的三条记录,再用ID回表查询,筛选出 name = “张三” 的记录。
如果使用索引下推,会先匹配出 age = 18 的三条记录,再筛选出 name = “张三” 的一条记录,最后再用ID回表查询。
由此得出,索引下推的优点:减少了回表的扫描行数。
**面试官: ** 小伙子,八股文背的挺溜啊。我给你出个实战题,看你有没有准备。下面这个查询SQL该怎么建联合索引?
select a from table where b = 1 and c = 2;
故意刁难我?你以为实战题就不能背八股文了吗?
我: 刚才在讲联合索引的时候已经说了这个知识点了,where条件有b和c的等值查询,联合索引就建成(b,c),由于select后面有a,我们就建立 (b,c,a) 的联合索引,并且可以用到覆盖索引,查询速度更快。
面试官: 小伙子,有点东西。一会儿就给你发offer,明天就来上班,薪资double。
文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。