面试官:MySQL 如何查找删除重复行?我竟然写不出来。。

本文讲述如何查找数据库里重复的行。这是初学者十分普遍遇到的问题。方法也很简单。这个问题还可以有其他演变,例如,如何查找“两字段重复的行”(#mysql IRC 频道问到的问题)
如何查找重复行
第一步是定义什么样的行才是重复行。多数情况下很简单:它们某一列具有相同的值。本文采用这一定义,或许你对“重复”的定义比这复杂,你需要对sql做些修改。本文要用到的数据样本:
create table test(id int not primary key, day date not null); insert into test(id, day) values(1, "2006-10-08"); insert into test(id, day) values(2, "2006-10-08"); insert into test(id, day) values(3, "2006-10-09"); select * from test; +----+------------+ | id | day | +----+------------+ | 1 | 2006-10-08 | | 2 | 2006-10-08 | | 3 | 2006-10-09 | +----+------------+
前面两行在day字段具有相同的值,因此如何我将他们当做重复行,这里有一查询语句可以查找。查询语句使用GROUP BY子句把具有相同字段值的行归为一组,然后计算组的大小。
select day, count(*) from test GROUP BY day; +------------+----------+ | day | count(*) | +------------+----------+ | 2006-10-08 | 2 | | 2006-10-09 | 1 | +------------+----------+
重复行的组大小大于1。如何希望只显示重复行,必须使用HAVING子句,比如
select day, count(*) from test group by day HAVING count(*) > 1; +------------+----------+ | day | count(*) | +------------+----------+ | 2006-10-08 | 2 | +------------+----------+
这是基本的技巧:根据具有相同值的字段分组,然后知显示大小大于1的组。
为什么不能使用WHERE子句?因为WHERE子句过滤的是分组之前的行,HAVING子句过滤的是分组之后的行。
如何删除重复行
一个相关的问题是如何删除重复行。一个常见的任务是,重复行只保留一行,其他删除,然后你可以创建适当的索引,防止以后再有重复的行写入数据库。
同样,首先是弄清楚重复行的定义。你要保留的是哪一行呢?第一行,或者某个字段具有最大值的行?本文中,假设要保留的是第一行——id字段具有最小值的行,意味着你要删除其他的行。
也许最简单的方法是通过临时表。尤其对于MYSQL,有些限制是不能在一个查询语句中select的同时update一个表。简单起见,这里只用到了临时表的方法。
我们的任务是:删除所有重复行,除了分组中id字段具有最小值的行。因此,需要找出大小大于1的分组,以及希望保留的行。你可以使用MIN()函数。这里的语句是创建临时表,以及查找需要用DELETE删除的行。
create temporary table to_delete (day date not null, min_id int not null); insert into to_delete(day, min_id) select day, MIN(id) from test group by day having count(*) > 1; select * from to_delete; +------------+--------+ | day | min_id | +------------+--------+ | 2006-10-08 | 1 | +------------+--------+
有了这些数据,你可以开始删除“脏数据”行了。可以有几种方法,各有优劣(详见我的文章many-to-one problems in SQL),但这里不做详细比较,只是说明在支持查询子句的关系数据库中,使用的标准方法。
delete from test where exists( select * from to_delete where to_delete.day = test.day and to_delete.min_id <> test.id )
如何查找多列上的重复行
有人最近问到这样的问题:我的一个表上有两个字段b和c,分别关联到其他两个表的b和c字段。我想要找出在b字段或者c字段上具有重复值的行。
咋看很难明白,通过对话后我理解了:他想要对b和c分别创建unique索引。如上所述,查找在某一字段上具有重复值的行很简单,只要用group分组,然后计算组的大小。并且查找全部字段重复的行也很简单,只要把所有字段放到group子句。但如果是判断b字段重复或者c字段重复,问题困难得多。这里提问者用到的样本数据
create table a_b_c( a int not null primary key auto_increment, b int, c int ); insert into a_b_c(b,c) values (1, 1); insert into a_b_c(b,c) values (1, 2); insert into a_b_c(b,c) values (1, 3); insert into a_b_c(b,c) values (2, 1); insert into a_b_c(b,c) values (2, 2); insert into a_b_c(b,c) values (2, 3); insert into a_b_c(b,c) values (3, 1); insert into a_b_c(b,c) values (3, 2); insert into a_b_c(b,c) values (3, 3);
现在,你可以轻易看到表里面有一些重复的行,但找不到两行具有相同的二元组{b, c}。这就是为什么问题会变得困难了。
错误的查询语句
如果把两列放在一起分组,你会得到不同的结果,具体看如何分组和计算大小。提问者恰恰是困在了这里。有时候查询语句找到一些重复行却漏了其他的。这是他用到了查询
select b, c, count(*) from a_b_c group by b, c having count(distinct b > 1) or count(distinct c > 1);
结果返回所有的行,因为CONT(*)总是1.为什么?因为 >1 写在COUNT()里面。这个错误很容易被忽略,事实上等效于
select b, c, count(*) from a_b_c group by b, c having count(1) or count(1);
为什么?因为(b > 1)是一个布尔值,根本不是你想要的结果。你要的是
select b, c, count(*) from a_b_c group by b, c having count(distinct b) > 1 or count(distinct c) > 1;
返回空结果。很显然,因为没有重复的{b,c}。这人试了很多其他的OR和AND的组合,用来分组的是一个字段,计算大小的是另一个字段,像这样
select b, count(*) from a_b_c group by b having count(distinct c) > 1; +------+----------+ | b | count(*) | +------+----------+ | 1 | 3 | | 2 | 3 | | 3 | 3 | +------+----------+
没有一个能够找出全部的重复行。而且最令人沮丧的是,对于某些情况,这种语句是有效的,如果错误地以为就是这么写法,然而对于另外的情况,很可能得到错误结果。
事实上,单纯用GROUP BY 是不可行的。为什么?因为当你对某一字段使用group by时,就会把另一字段的值分散到不同的分组里。对这些字段排序可以看到这些效果,正如分组做的那样。首先,对b字段排序,看看它是如何分组的
当你对b字段排序(分组),相同值的c被分到不同的组,因此不能用COUNT(DISTINCT c)来计算大小。COUNT()之类的内部函数只作用于同一个分组,对于不同分组的行就无能为力了。类似,如果排序的是c字段,相同值的b也会分到不同的组,无论如何是不能达到我们的目的的。
几种正确的方法
也许最简单的方法是分别对某个字段查找重复行,然后用UNION拼在一起,像这样:
select b as value, count(*) as cnt, "b" as what_col from a_b_c group by b having count(*) > 1 union select c as value, count(*) as cnt, "c" as what_col from a_b_c group by c having count(*) > 1; +-------+-----+----------+ | value | cnt | what_col | +-------+-----+----------+ | 1 | 3 | b | | 2 | 3 | b | | 3 | 3 | b | | 1 | 3 | c | | 2 | 3 | c | | 3 | 3 | c | +-------+-----+----------+
输出what_col字段为了提示重复的是哪个字段。另一个办法是使用嵌套查询:
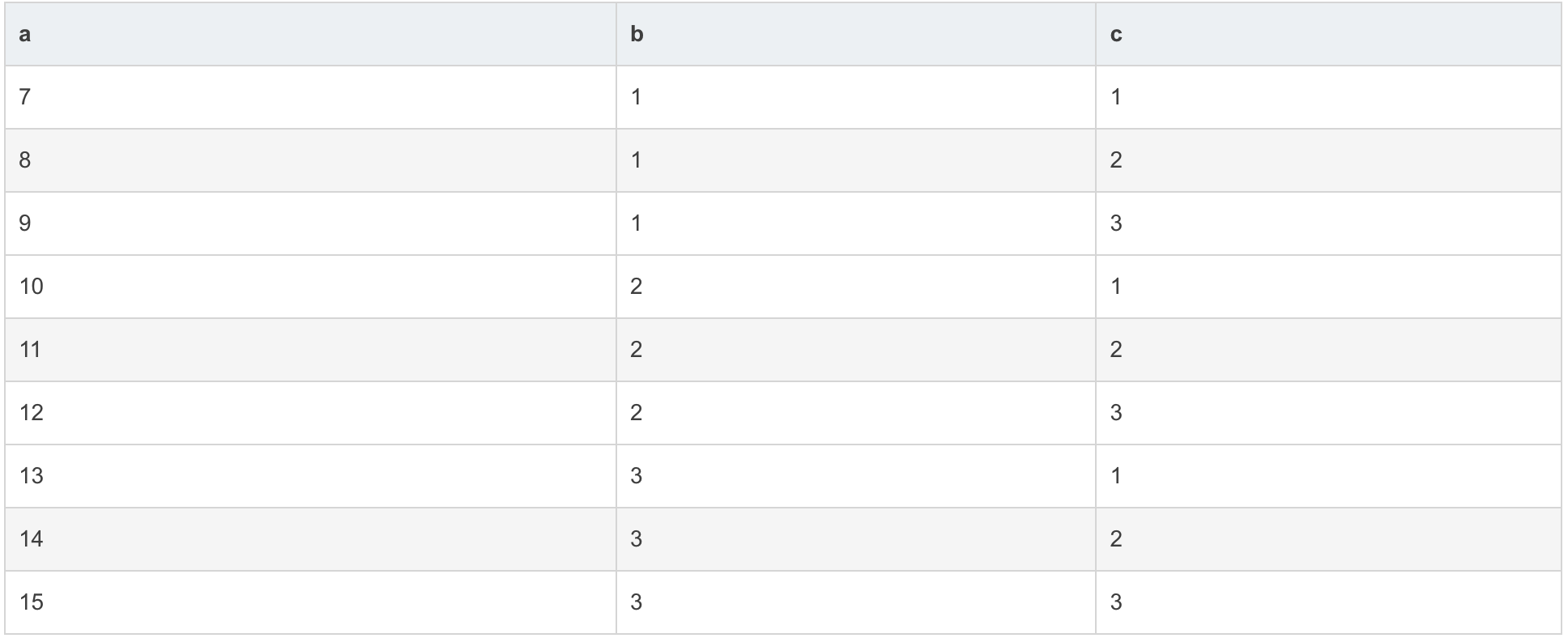
select a, b, c from a_b_c where b in (select b from a_b_c group by b having count(*) > 1) or c in (select c from a_b_c group by c having count(*) > 1); +----+------+------+ | a | b | c | +----+------+------+ | 7 | 1 | 1 | | 8 | 1 | 2 | | 9 | 1 | 3 | | 10 | 2 | 1 | | 11 | 2 | 2 | | 12 | 2 | 3 | | 13 | 3 | 1 | | 14 | 3 | 2 | | 15 | 3 | 3 | +----+------+------+
这种方法的效率要比使用UNION低许多,并且显示每一重复的行,而不是重复的字段值。还有一种方法,将自己跟group的嵌套查询结果联表查询。写法比较复杂,但对于复杂的数据或者对效率有较高要求的情况,是很有必要的。
select a, a_b_c.b, a_b_c.c from a_b_c left outer join ( select b from a_b_c group by b having count(*) > 1 ) as b on a_b_c.b = b.b left outer join ( select c from a_b_c group by c having count(*) > 1 ) as c on a_b_c.c = c.c where b.b is not null or c.c is not null
以上方法可行,我敢肯定还有其他的方法。如果UNION能用,我想会是最简单不过的了。
作者:愤怒的韭菜
来源:https://blog.csdn.net/zhengzhb/article/details/8590390
原文:http://www.xaprb.com/blog/2006/10/09/how-to-find-duplicate-rows-with-sql/
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
2.劲爆!Java 协程要来了。。。
3.Spring Boot 2.x 教程,太全了!
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
5.《Java开发手册(嵩山版)》最新发布,速速下载!
觉得不错,别忘了随手点赞+转发哦!