Python数据分析之concat与merge函数(实例详解)

本篇文章给大家带来了关于python的相关知识,其中主要介绍了关于数据合并的相关问题,包括了concat函数与merge函数等内容,下面一起来看一下,希望对大家有帮助。

推荐学习:python视频教程
一、concat函数
- concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=None, copy=True) - 参数含义如下:
| 参数 | 作用 |
|---|---|
| axis | 表示连接的轴向,可以为0或者1,默认为0 |
| join | 表示连接的方式,inner表示内连接,outer表示外连接,默认使用外连接 |
| ignore_index | 接收布尔值,默认为False。如果设置为True,则表示清除现有索引并重置索引值 |
| keys | 接收序列,表示添加最外层索引 |
| levels | 用于构建MultiIndex的特定级别(唯一值) |
| names | 设置了keys和level参数后,用于创建分层级别的名称 |
| verify_integerity | 检查新的连接轴是否包含重复项。接收布尔值,当设置为True时,如果有重复的轴将会抛出错误,默认为False |
- 根据轴方向的不同,可以将堆叠分成横向堆叠与纵向堆叠,默认采用的是纵向堆叠方式
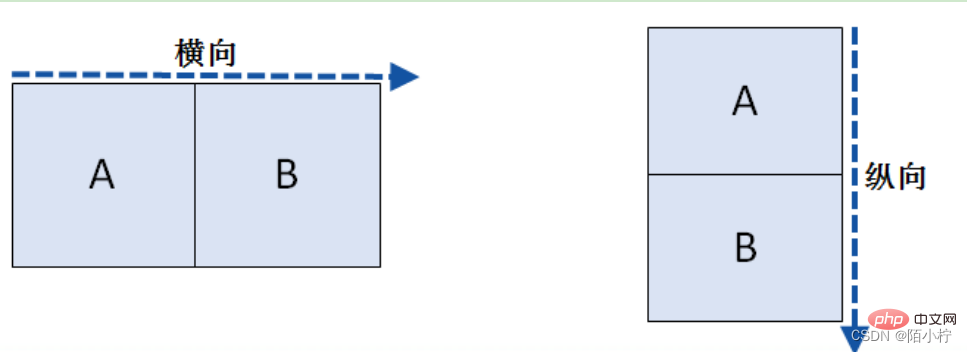
- 在堆叠数据时,默认采用的是外连接(join参数设为outer)的方式进行合并,当然也可以通过join=inner设置为内连接的方式。
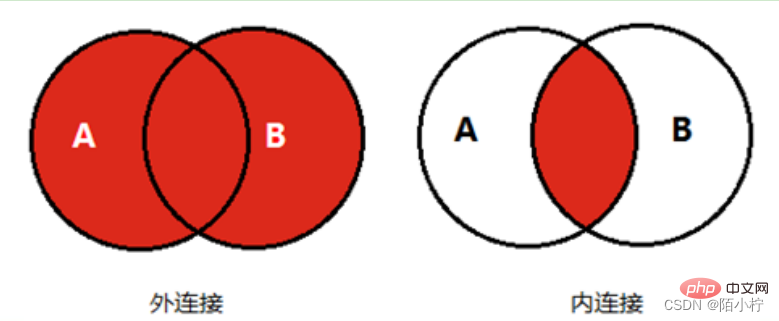
1)横向堆叠与外连接
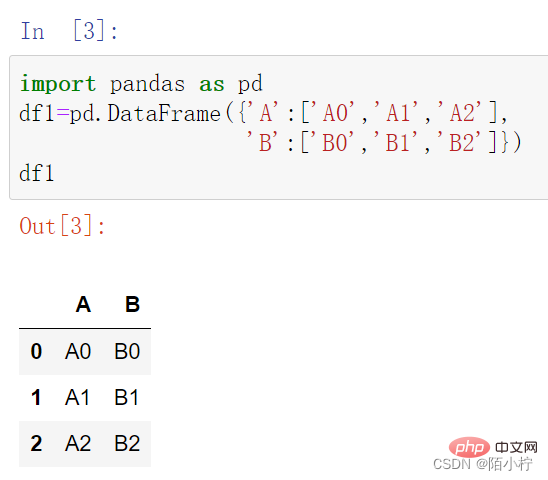
import pandas as pd
df1=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})df1
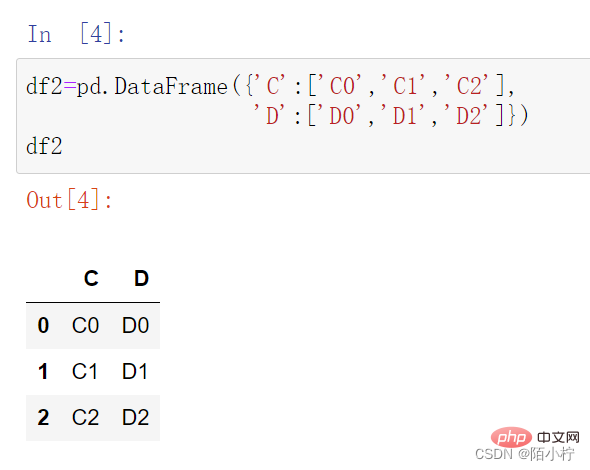
df2=pd.DataFrame({'C':['C0','C1','C2'],
'D':['D0','D1','D2']})df2
横向堆叠合并df1和df2,采用外连接的方式
pd.concat([df1,df2],join='outer',axis=1)

2) 纵向堆叠与内链接
import pandas as pd
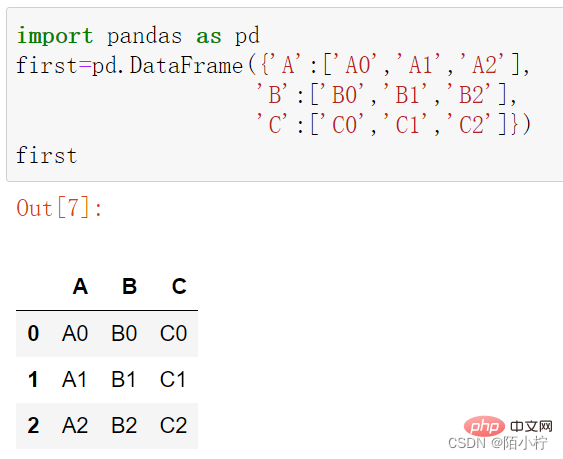
first=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2'],
'C':['C0','C1','C2']})first
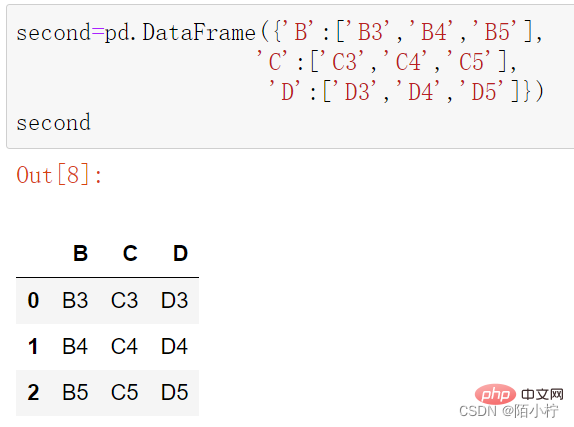
second=pd.DataFrame({'B':['B3','B4','B5'],
'C':['C3','C4','C5'],
'D':['D3','D4','D5']})second
- 当使用concat()函数合并时,若是将axis参数的值设为0,且join参数的值设为inner,则代表着使用纵向堆叠与内连接的方式进行合并
pd.concat([first,second],join='inner',axis=0)

二、merge()函数
1)主键合并数据
- 在使用merge()函数进行合并时,默认会使用重叠的列索引做为合并键,并采用内连接方式合并数据,即取行索引重叠的部分。
import pandas as pd
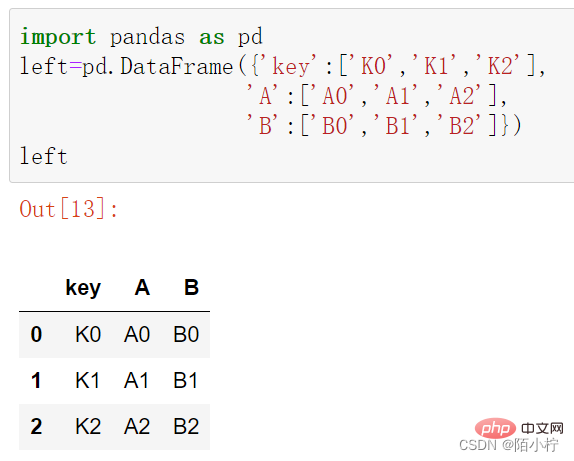
left=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})left
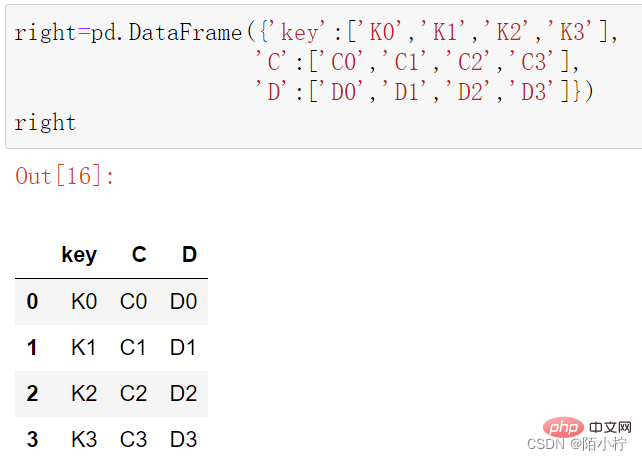
right=pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})right
pd.merge(left,right,on='key')

2)merge()函数还支持对含有多个重叠列的DataFrame对象进行合并。
import pandas as pd
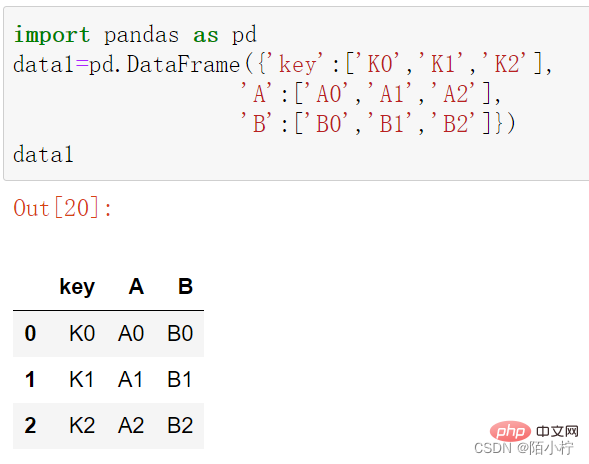
data1=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})data1
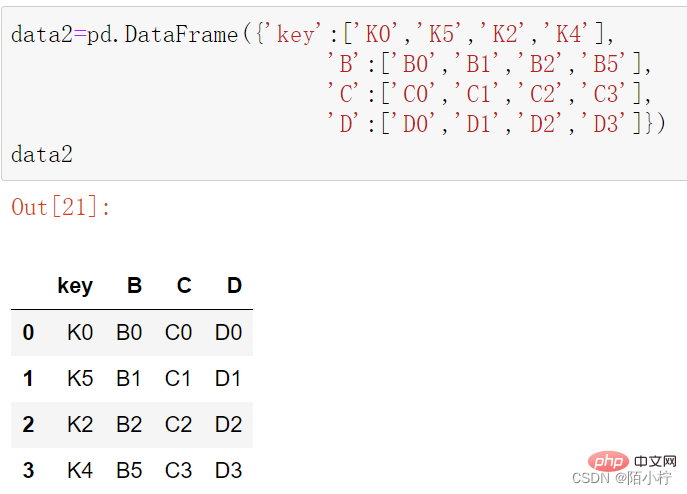
data2=pd.DataFrame({'key':['K0','K5','K2','K4'],
'B':['B0','B1','B2','B5'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})data2
pd.merge(data1,data2,on=['key','B'])

1)根据行索引合并数据
- join()方法能够通过索引或指定列来连接多个DataFrame对象
- join(other,on = None,how =‘left’,lsuffix =‘’,rsuffix =‘’,sort = False )
| 参数 | 作用 |
|---|---|
| on | 名称,用于连接列名 |
| how | 可以从{‘‘left’’ ,‘‘right’’, ‘‘outer’’, ‘‘inner’’}中任选一个,默认使用左连接的方式。 |
| sort | 根据连接键对合并的数据进行排序,默认为False |
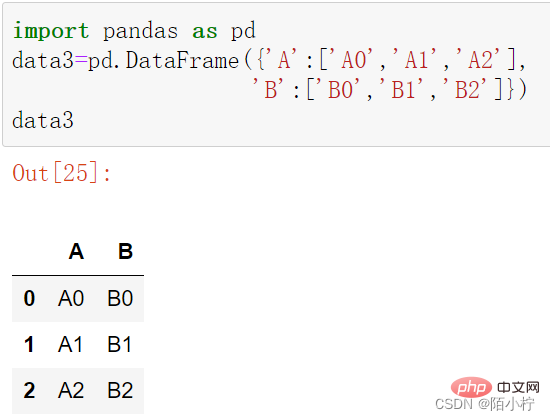
import pandas as pd
data3=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})data3
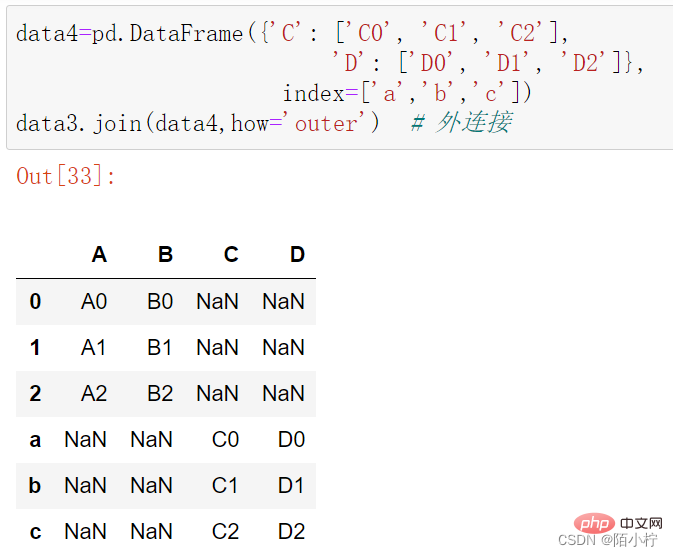
data4=pd.DataFrame({'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']},
index=['a','b','c'])data3.join(data4,how='outer') # 外连接
data3.join(data4,how='left') #左连接

data3.join(data4,how='right') #右连接

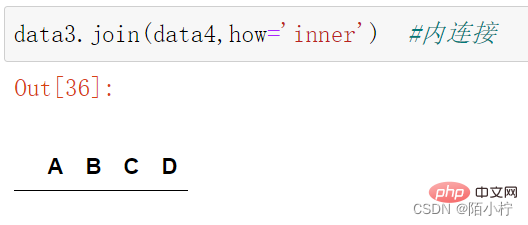
data3.join(data4,how='inner') #内连接
import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'key': ['K0', 'K1', 'K2']})left

right = pd.DataFrame({'C': ['C0', 'C1','C2'],
'D': ['D0', 'D1','D2']},
index=['K0', 'K1','K2'])right

on参数指定连接的列名
left.join(right,how='left',on='key') #on参数指定连接的列名

2)合并重叠数据
当DataFrame对象中出现了缺失数据,而我们希望使用其他DataFrame对象中的数据填充缺失数据,则可以通过combine_first()方法为缺失数据填充。
import pandas as pdimport numpy as npfrom numpy import NAN
left = pd.DataFrame({'A': [np.nan, 'A1', 'A2', 'A3'],
'B': [np.nan, 'B1', np.nan, 'B3'],
'key': ['K0', 'K1', 'K2', 'K3']})left

right = pd.DataFrame({'A': ['C0', 'C1','C2'],
'B': ['D0', 'D1','D2']},
index=[1,0,2])right

用right的数据填充left缺失的部分
left.combine_first(right) # 用right的数据填充left缺失的部分

推荐学习:python视频教程
