Spring 源码(6)BeanFactoryPostProcessor怎么执行的?


上一篇文章 https://www.cnblogs.com/redwinter/p/16167214.html 解读了如何进行自定义属性值的编辑器的解析器,并且还介绍了BeanFactory的准备过程中做了哪些事情。这篇文章继续介绍AbstractApplicationContext#refresh的方法。
AbstractApplicationContext提供的postProcessBeanFactory空方法
postProcessBeanFactory这个方法没名字跟BeanFactoryPostProcessor接口中的方法一样,但是他的功能是提供给子类进行添加一些额外的功能,比如添加BeanPostProcessor接口的实现,或者定制一些其他的功能也是可以的,因为这个方法你可以拿到BeanFactory,自然是可以对他进行一些功能的定制的。
这里看下Spring 提供的子类GenericWebApplicationContext是如何实现的:
@Override
protected void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
if (this.servletContext != null) {
beanFactory.addBeanPostProcessor(new ServletContextAwareProcessor(this.servletContext));
beanFactory.ignoreDependencyInterface(ServletContextAware.class);
}
WebApplicationContextUtils.registerWebApplicationScopes(beanFactory, this.servletContext);
WebApplicationContextUtils.registerEnvironmentBeans(beanFactory, this.servletContext);
}
这里他注册了一个ServletContextAwreProcessor 到beanFactory中,ServletContexAwareProcessor是一个BeanPostProcessor接口的子类。
重头戏BeanFactoryPostProcessor
接下来分析AbstractApplicationContext#refresh中的invokeBeanFactoryPostProcessors方法,这个方法用来注册和执行BeanFactoryPostProcessor的。
直接上源码:
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
// 执行所有的BeanFactoryPostProcessor
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
// aop的处理
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
重点在这里:
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
首先获取BeanFactoryPostProcessor的集合,这里获取到都是用户在定制BeanFactory时add加入进去的,进入这个方法:
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
// 已经处理的Bean
Set<String> processedBeans = new HashSet<>();
// 先进性外部BFPP的处理,并且判断当前Factory是否是BeanDefinitionRegistry
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
// 保存BFPP的Bean
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
// 保存BDRPP的Bean
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
// 开始处理外部传入的BFPP
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
// 先处理BDRPP
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
// 直接调用BDRPP的接口方法,后面的postProcessBeanFactory 方法后面统一处理
registryProcessor.postProcessBeanDefinitionRegistry(registry);
// 加入到BFPP的集合中
registryProcessors.add(registryProcessor);
}
else {
// 加入到BDRPP的集合中
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
// 保存当前的BDRPP
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
// 按类型获取BeanName
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 判断当前的beanName是都是实现了PriorityOrdered
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
// 加入到当前注册的BDRPP集合中
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 加入到已经处理的bean集合中
processedBeans.add(ppName);
}
}
// 对当前的BDRPP进行排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 将当前的BDRPP全部加入到最前面定义的BDRPP的集合中
registryProcessors.addAll(currentRegistryProcessors);
// 执行当前的BDRPP的postProcessBeanDefinitionRegistry方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// 清空当前的BDRPP
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
// 再次获取bdrpp,因为上面的执行可能还会加入新的bdrpp进来
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 判断是否已经处理过,并且是否实现了Ordered接口
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
// 加入到当前的BDRPP的集合中
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 添加到已经处理的集合中
processedBeans.add(ppName);
}
}
// 排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 加入到BDRPP集合中
registryProcessors.addAll(currentRegistryProcessors);
// 执行bdrpp的postProcessBeanDefinitionRegistry方法
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// 清空当前bdrpp集合
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
// 循环去获取BDRPP,然后进行排序、执行操作,直到所有的BDRPP全部执行完
while (reiterate) {
reiterate = false;
// 获取BDRPP
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 如果已经处理过,就执行BDRPP,并且退出循环,否则继续循环
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
// 排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
// 加入到BDRPP集合中
registryProcessors.addAll(currentRegistryProcessors);
// 执行bdrpp
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
// 执行bdrpp 中的postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
// 执行bfpp 中的postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// 如果不是bdrpp,那么直接执行bfpp的postProcessBeanFactory
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// 获取BFPP的beanName集合
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
// 定义实现了PriorityOrdered的BFPP
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
// 定义实现了Ordered接口的集合
// List<String> orderedPostProcessorNames = new ArrayList<>();
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
// 定义没有排序的集合
// List<String> nonOrderedPostProcessorNames = new ArrayList<>();
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String ppName : postProcessorNames) {
// 如果已经处理过了就不做处理
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
// orderedPostProcessorNames.add(ppName);
orderedPostProcessors.add(beanFactory.getBean(ppName,BeanFactoryPostProcessor.class));
}
else {
// nonOrderedPostProcessorNames.add(ppName);
nonOrderedPostProcessors.add(beanFactory.getBean(ppName,BeanFactoryPostProcessor.class));
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
// 排序
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 先执行PriorityOrdered接口的bfpp
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
// 这里将上面获取到Ordered接口的BFPP进行集合转换,然后排序,然后执行,这里其实可以直接合并,
// 在上述进行获取时就放在这个orderedPostProcessors集合中
// List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
// for (String postProcessorName : orderedPostProcessorNames) {
// orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
// }
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
// 处理没有排序的
// List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
// for (String postProcessorName : nonOrderedPostProcessorNames) {
// nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
// }
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
// 清除缓存的元数据,因为经过BFPP的执行,可能BeanDefinition的属性值已经个变化,比如使用占位符的属性值
beanFactory.clearMetadataCache();
}
这个方法大概很长,实际上就做了一下这么几点事情:
- 先执行外部传入的
BeanFactoryPostProcessor的实现 - 处理时先处理
BeanFactoryPostProcessor的子接口BeanDefinitionRegistryPostProcessor的实现 - 处理
BeanDefinitionRegistryPostProcessor实现的时候先处理实现了PriorityOrdered接口的实现 - 处理完
PriorityOrdered接口实现的类之后再处理实现了Ordered接口的实现 - 处理完
Ordered接口的实现类之后处理没有排序的 - 处理完
BeanDefinitionRegistryPostProcessor的实现之后处理BeanFactoryPostProcessor的实现 - 处理顺序也是
PriorityOreded,Ordered,没有排序的
这里大概逻辑就是这个,看起来可能不是很懂,画个流程图:
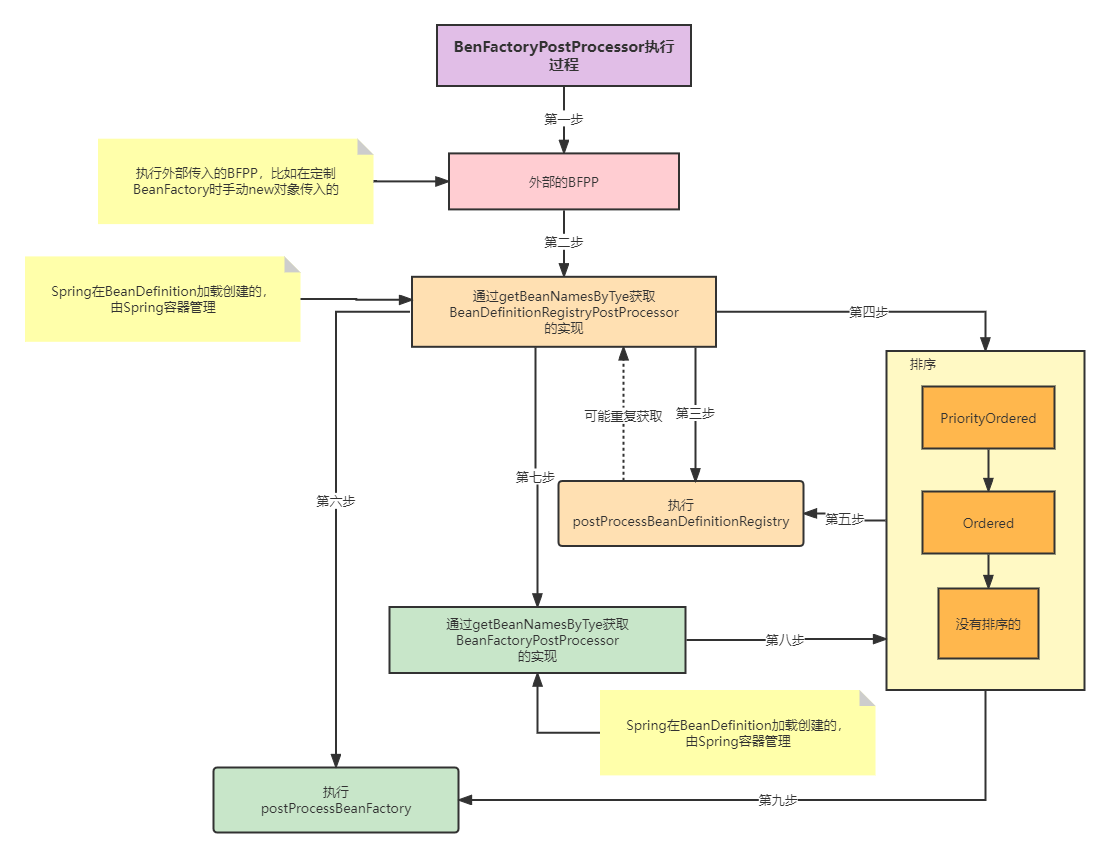
通过流程图可以简化为:先遍历执行外部传入的BFPP,再执行BDRPP,再执行BFPP三部分,处理每一部分可能会进行排序操作,排序按照PriorityOrdered,Ordered,noSort进行排序再执行。
这里解释下BeanDefinitionRegistryPostProcessor,这个接口是BeanFactoryPostProcessor,它里面包含一个方法叫postProcessBeanDefinitionRegistry,这个方法非常重要,在实现类ConfigurationClassPostProcessor中就是使用这个方法进行注解的解析的,而且这个类也是实现SpringBoot自动装配的关键。
ConfigurationClassPostProcessor这个类是什么时候加入到Spring容器的呢?
在我们启动容器的时候,Spring会进行BeanDefinition的扫描,如果我们在xml配置文件中开启了注解扫描:
<context:component-scan base-package="com.redwinter.test"/>
那么这个时候就会自动添加多个BeanDefinition到Spring容器中,beanName为org.springframework.context.annotation.internalConfigurationAnnotationProcessor,其他还有几个:

前面的文章 https://www.cnblogs.com/redwinter/p/16165878.html 讲到自定义标签,在spring解析xml时分为默认的命名空间和自定义的命名空间的,而context就是自定义的命名空间,这个标签的解析器为ComponentScanBeanDefinitionParser,这个类中的parse方法就是解析逻辑处理:
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
// 配置扫描器
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
// 扫描BeanDefinition,在指定的包下
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
// 注册组件
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
这个方法执行流程:
- 创建一个配置扫描器
- 扫描指定包下标有注解的类并解析为
BeanDefinition - 执行
registerComponents方法,注册组件
registerComponents方法里面就是添加ConfigurationClassPostProcessor的地方,由于代码太多这里只贴部分代码:
// ...省略部分代码
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
// 判断注册器中个是否包含org.springframework.context.annotation.internalConfigurationAnnotationProcessor
// 不包含就加入一个ConfigurationClassPostProcessor的BeanDefinition
// 用于解析注解
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
// 创建一个BeanDefinition为ConfigurationClassPostProcessor
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
// 注册一个beanName为org.springframework.context.annotation.internalConfigurationAnnotationProcessor
// 的BeanDefinition,class为ConfigurationClassPostProcessor
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 创建一个AutowiredAnnotationBeanPostProcessor的BeanDefinition
// 用于自动装配
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// ...省略部分代码
源码中注册了一个beanName为CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME常量的名字,这个常量就是org.springframework.context.annotation.internalConfigurationAnnotationProcessor,class为ConfigurationClassPostProcessor
那注解的解析是如何进行解析的呢?由于篇幅过长,下一篇再来解析。
