怎么得到tuphub.today热榜和热度呢?

用到的模块有:requesst、re、pandas
步骤:1.得到url
2.设置请求头伪装浏览器,防止被反爬
3.请求获得文本文件
4.用re.compile()方法复制文本
5.用pd.DataFrame()让爬取的信息根据可读性,条理性。
import requests
import re
import pandas as pd
url = "https://tophub.today/n/Jb0vmloB1G"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
" AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44"
}
r = requests.get(url,headers=headers).text # 得到text文本。
title = re.compile("itemid="[0-9]*">(.*?)</a>") # 这些信息在网页开发者模式下可以获取
titles = title.findall(r)[0:31] # 用findall方法和切片获得1-30的排行榜
num = re.compile("<td>(.*?)</td>") #复制热度信息
nums = num.findall(r)[0:31]
m = {"今日热点":titles,"热度":nums}
file = pd.DataFrame(m) # 使用DataFrame方法使爬取的数据更具可读性。
print(file)
爬取后的样子:
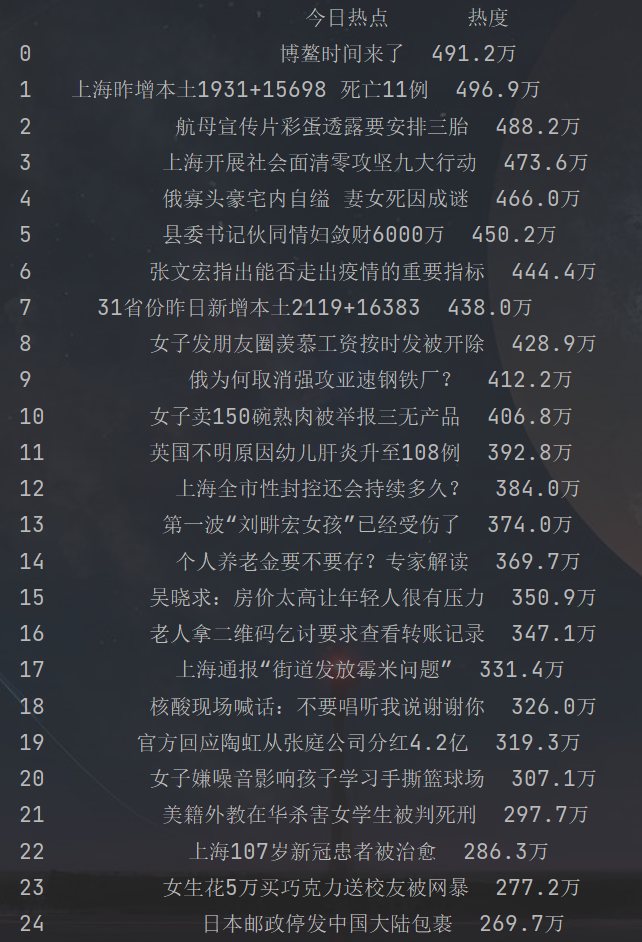
如果你把这段代码复制运行,你可能会发现爬取不到,因为热榜信息在更新,写的不太严谨,因为作者见解有限,在不断学习中,有啥不足或者补充的,欢迎各位大佬评论!

